2023年,nvim以及其生态已经发展的愈来愈完善了。nvim内置的LSP(以及具体的语言服务)加上众多插件,可以搭建出支持各种类型语法检查、代码补全、代码格式化等功能的IDE。网络上关于如何配置的文章很多,但本人发现绝大多数的文章仅仅停留在配置本身,没有深入的解释这些插件的作用和它们之间的关系,这就导致了很多入门的小伙伴在配置、使用的过程中遇到各种问题也不知如何下手。本文将手把手,一步一步的演进并解释,帮助小伙伴了解这块的内容。
注意1:本文主要探讨nvim关于LSP、null-ls以及代码补全内容,不会详细介绍如何使用插件系统。
注意2:本文阅读前需要读者已经掌握了如何使用插件管理器来安装插件并setup插件配置。
认识LSP
在本文的开始,让我们先介绍一下LSP(Language Server Protocol,语言服务协议)。当然,网络上有很多详细的介绍LSP的内容,本文不会深入介绍它的实现机制,仅作为本文的入门的解释。
简单来讲,该协议定义了两端:Language Client(语言服务客户端)和Language Server(语言服务端),其核心是将代码编辑器文本界面的展示和**代码语言分析(语言支持,自动补全,定义与引用解析等)**解耦。通常,我们的文本编辑器就是一个客户端,而各种语言的解析则会有对应LSP协议实现的服务端。
为了让读者更加清楚的理解LSP的运作,我们编写有如下TypeScript代码:
1 | |
上述这段代码首先定义了一个名为User的接口(interface User),该接口拥有一个字段name;然后,我们创建了一个基于User接口的user实例;最后,我们打印了user的age属性。user并不具备age字段,所以按照严格的TypeScript语言规范来讲,代码编译肯定会有错误:

基于LSP的模型,我们可以将这个过程描述出来:
- 在编辑器上写入上述的TS代码;
- 编辑器将上述代码通过某种通讯协议发送给TypeScript语言服务器;
- TS语言服务读取TS代码,进行语法检查,得到了编译错误信息(包含行列数,基本的建议提示信息)返回给编辑器;
- 编辑器接收到错误信息,通过自己的方式展示在编辑器UI上。
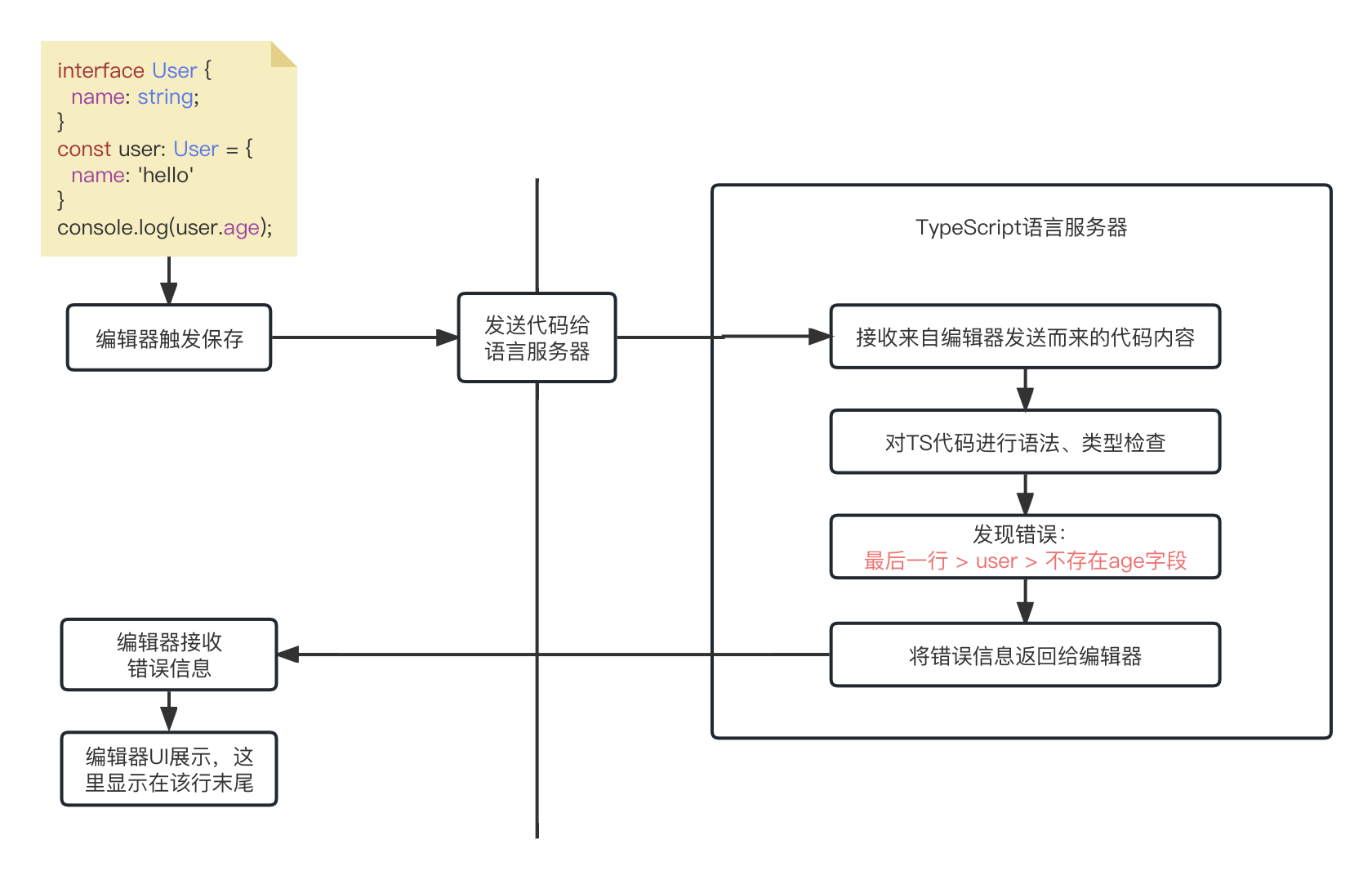
现在,我们已经了解了基于LSP的代码分析处理流程,那么这个语言服务器在什么地方呢?首先,不要看到服务器三个字,就认为它一定是一个在远端的Web应用服务,语言服务器一般就是一个软件程序,只不过它能够处理专门解析你编写的程序代码,并做出响应。
使用LSP这套体系,有两个必备步骤:
- 获取并安装语言服务器程序;
- 启动语言服务器,让它处于运行状态。
有些语言服务器基于js编写实现,它一般是一个NPM包,我们以npm -g全局安装的形式安装它(例如TypeScript的语言服务器的实现typescript-language-server);有的语言服务器直接就是可执行程序(例如lua语言服务器lua-language-server),我们从网络上下载它存放到电脑上。通常,我们会把它们的可执行文件路径加入到环境变量中,以便随时在命令行中启动它们。启动以后,它就在一个进程中默默的的等待着客户端(也就是编辑器)链接,并在建立连接以后,进行代码的分析处理工作。
nvim中的LSP
了解了LSP的基本概念以后,接下来我们介绍在nvim中的LSP模块。在nvim 0.5+版本以后,已经内置了语言服务客户端的接口(Lsp - Neovim docs,注意只是语言服务客户端部分),比较常用的API:
- vim.lsp.buf.hover():代码的TIPS悬浮展示。
- vim.lsp.buf.format():代码格式化。
- vim.lsp.buf.references():当前代码符号的引用查询。
- vim.lsp.buf.implementation():当前代码(主要是函数方法)的实现定位。
- vim.lsp.buf.code_action():当前代码的一些优化操作。
但需要注意,上述这些都是接口方法,它只是一个封装后的壳子方法,不具备具体的实现。具体的实现,需要为每一个编程语言单独配置。也就是说,nvim内置的lsp模块的运行架构如下:
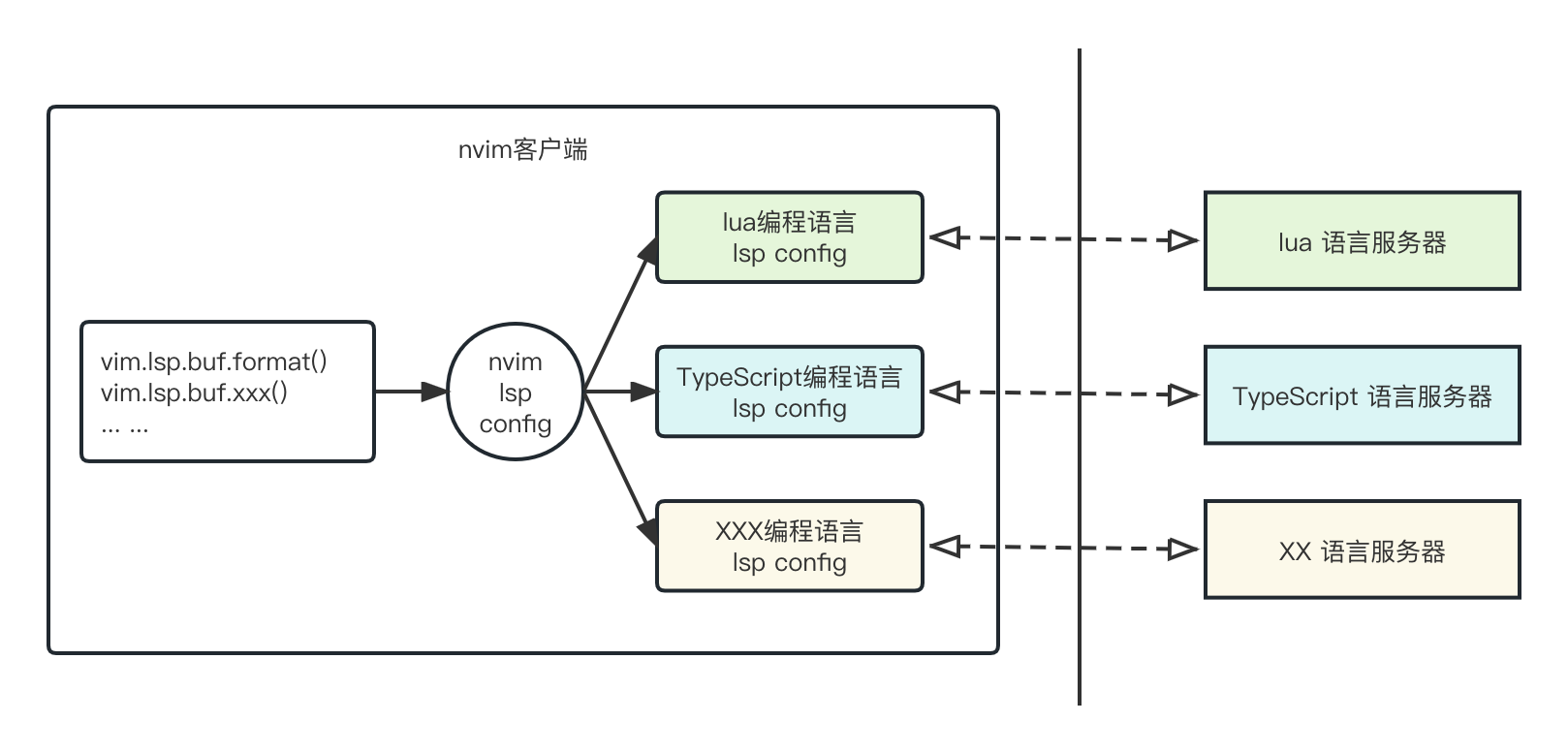
面对不同的语言,我们按照对应的语言服务的要求来配置nvim的内置LSP模块。在官方的文档中给了如下的示例来启动一个LSP:
1 | |
这段代码不过多赘述,因为它比起即将介绍的lspconfig插件来说,使用起来更加复杂。
nvim-lspconfig
每当有一个编程语言需要使用LSP的时候,我们都需要形如上述的nvim原生LSP配置来启动对应的语言服务器,同时还需要关注很多细节,譬如,你要手动启动它等等,这一点从用户体验上是比较不友好的。
为了更加方便快速的使用nvim的LSP模块,nvim官方提供了neovim/nvim-lspconfig这个插件。安装了这个插件以后,我们只需要进行少量且易于理解的配置,就能通过这个插件方便快捷的启动并使用语言服务了。
nvim-lspconfig通过插件管理器安装以后,我们就可以通过require的方式获取它,并通过它来配置某个编程语言的语言服务客户端。在lazy.nvim插件管理器下,配置如下:
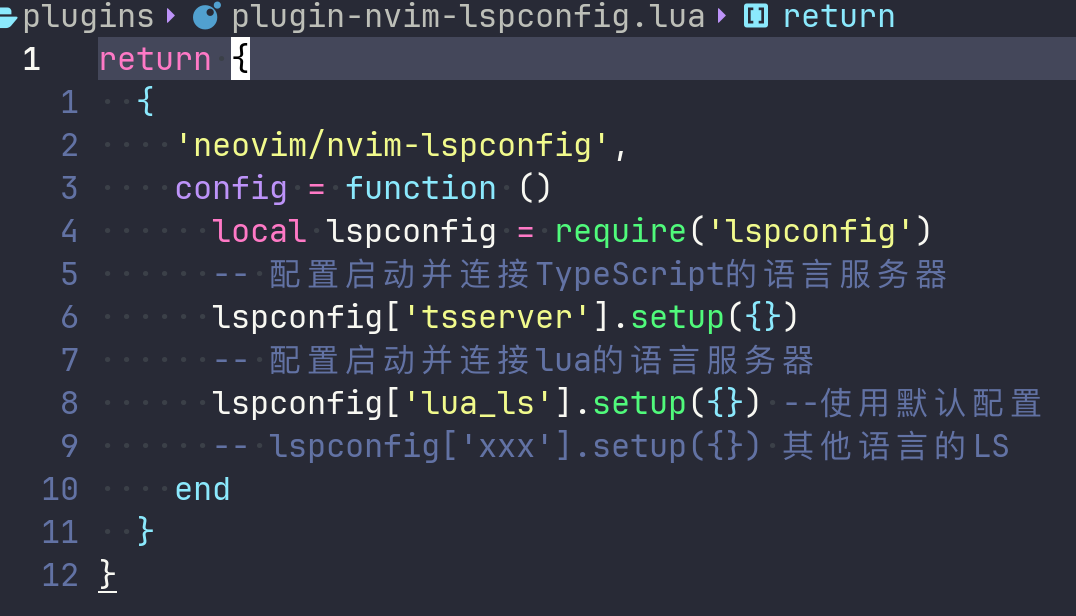
本人使用lazy.nvim来管理插件。上述第一行的
"neovim/nvim-lspconfig"代表要安装该插件;紧接着的config需要编写一个函数,代表插件安装后的配置阶段的自定义运行过程(详见lazy.nvim的文档),这个方法在nvim每次启动后,会被lazy.nvim调用,我们一般会在这个config的回调方法中获取插件实例调用其相关API进行配置。
无论使用何种插件管理器,nvim-lspconfig的使用流程都是一样:
- 安装nvim-lspconfig插件(通过lazy.nvim、packer等插件管理器,甚至是纯手工安装);
- 在确保该插件安装完成后的某个时机,获取nvim-lspconfig插件实例(
require('lspconfig')),这个插件实例可以访问不同编程语言的语言服务客户端对象(例如上面的lspconfig['tsserver']),每一个语言服务客户端对象都会有setup方法,我们只需要通过这个方法传入对该语言的语言服务配置。
当然, 如果setup里面什么都不传,它会使用默认配置进行setup。像上面的lspconfig['tsserver'],它其实就是针对TypeScript代码的语言服务配置,默认配置如下:

cmd代表了在我们机器上安装的语言服务器的命令行启动方式,比如在我们机器上启动TypeScript的语言服务,则会调用命令:typescript-language-server --stdio。
filetypes代表了当遇到哪些文件类型的时候,会让语言服务建立连接。在本例中,只要你打开的文件类型是javascript、typescript等,就会建立编辑器客户端与语言服务的连接,连接完成以后,就能进行查看类型定义、格式化等语言处理操作了。
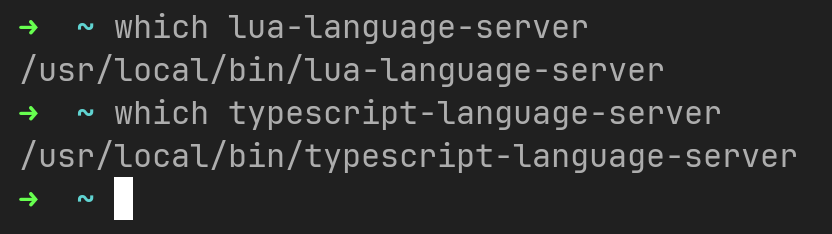
为了真的能启动语言服务器,我们按照文档提到的方式手动安装TypeScript和lua的语言服务器。在我的机器上,安装好以后,能够通过命令行方式访问得到:
让我们来梳理下上述demo的现状:
- 我们使用了0.5版本以上的nvim,它拥有内建的支持LSP客户端的模块;
- 我们安装了nvim-lspconfig插件,并在通过配置,让它在加载以后,又去setup了TypeScript和lua的语言服务配置;
- 我们在电脑上外部安装了TypeScript和lua的语言服务器,能够通过命令行访问到。
步骤1、2保证了我们的nvim具备了成为语言服务客户端的能力;步骤3保证了我们的电脑环境安装了所需要的语言服务器。
此时,当我们打开一个TS代码的时候,命令模式下键入LspInfo,就会看到如下的信息:
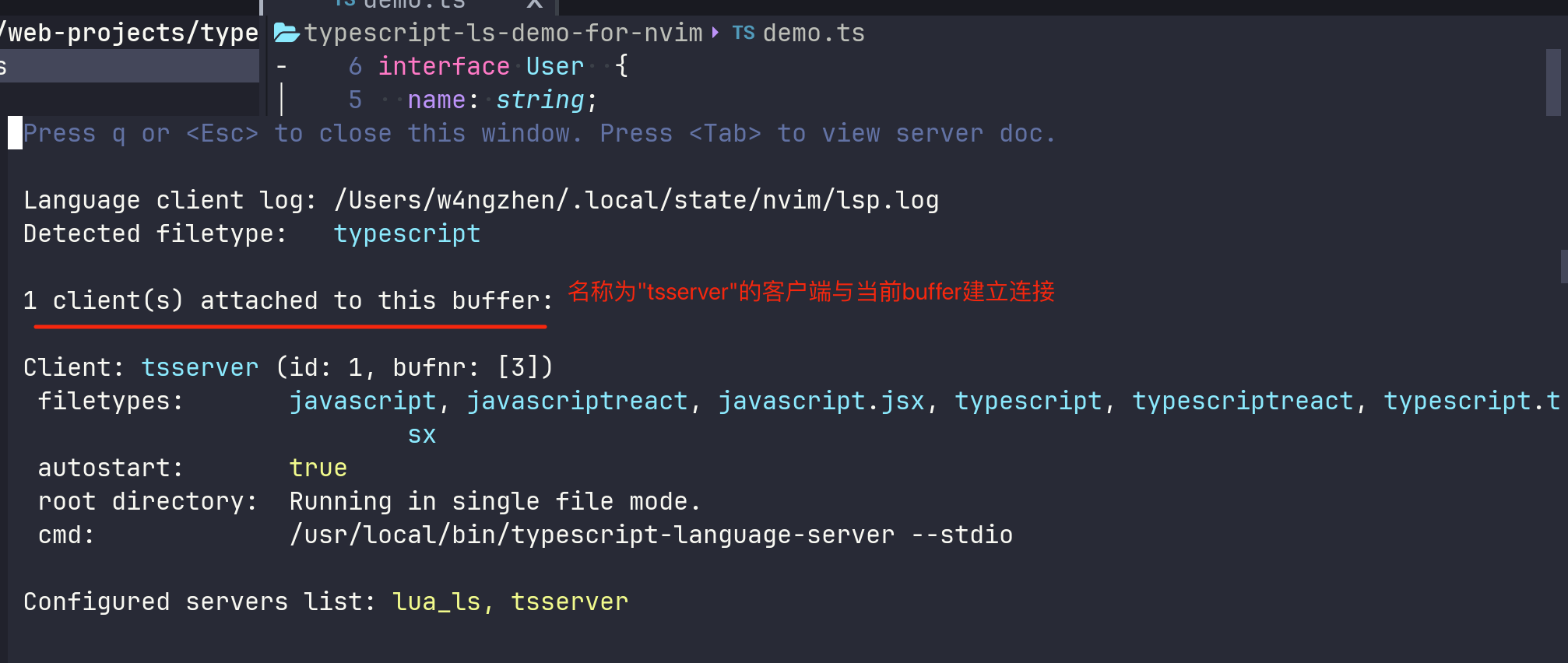
弹出信息告诉我们,有一个tsserver关联到了当前buffer(也就是这个demo.ts文件)。另外,在最后一行还能看到nvim-lspconfig显示了当前已经经过配置的语言服务有前面提到的lua_ls和tsserver。
一个buffer会有多个语言服务的客户端关联吗?
当然,比如一个文件里面既有TypeScript代码,又有css module(
import styles from './index.module.css'),当我们把cssmodules的语言服务器配置进来时候,这份js文件打开的时候,就会同时被两个语言服务客户端关联,由两个语言服务器分析当前的代码内容了。
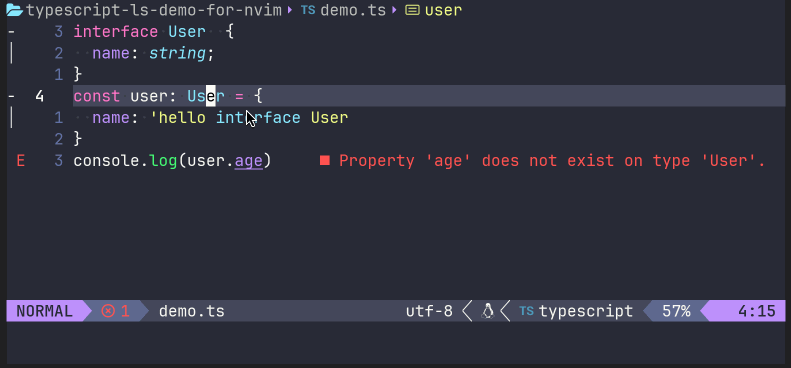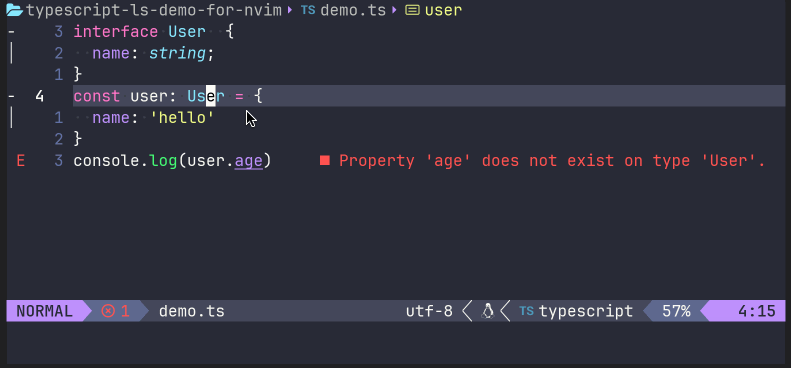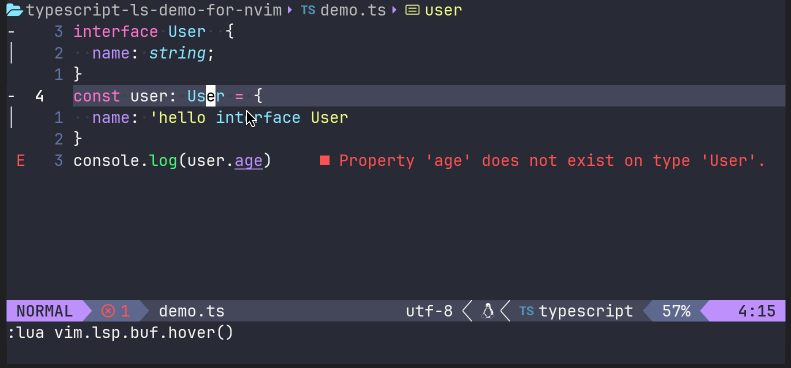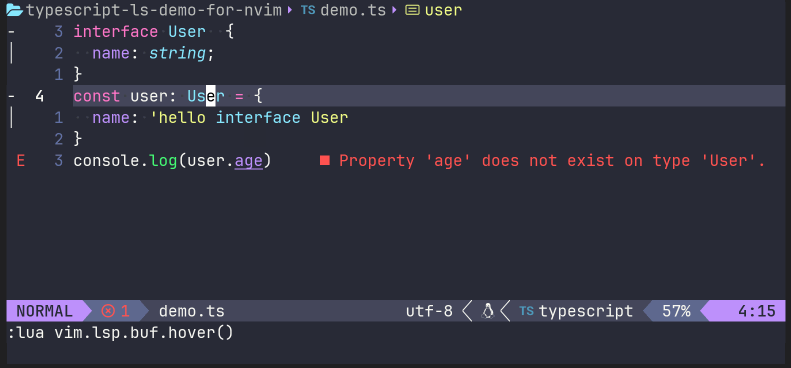
同时,我们可以测试一下LSP功能。譬如,将光标移动到user: User的接口User上时候,在命令模式下输入lua vim.lsp.buf.hover(),就能出现一个接口描述描述:
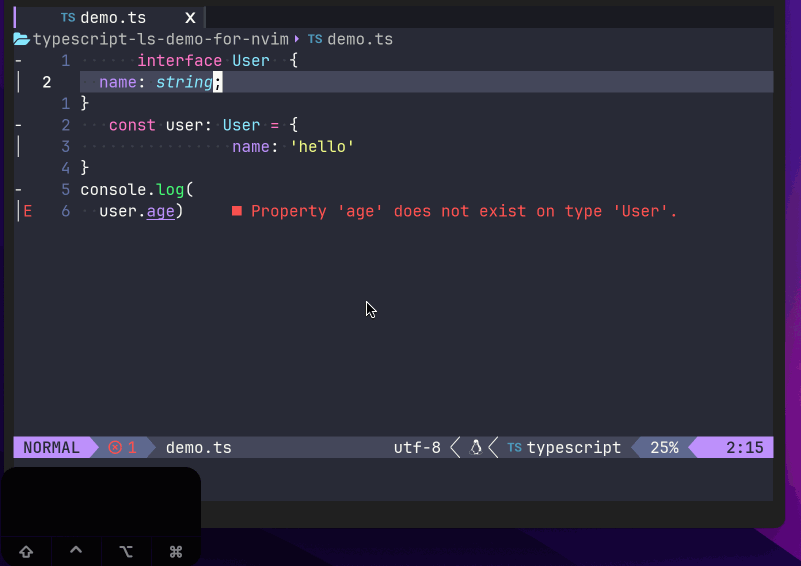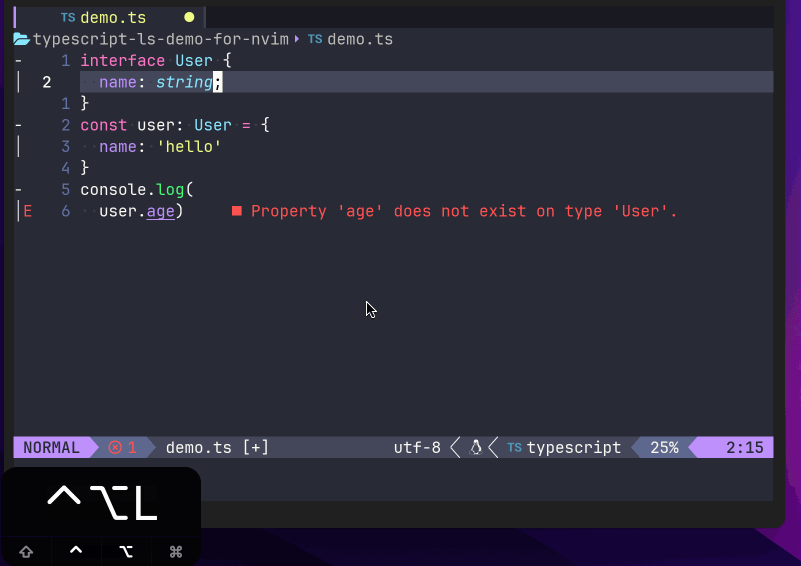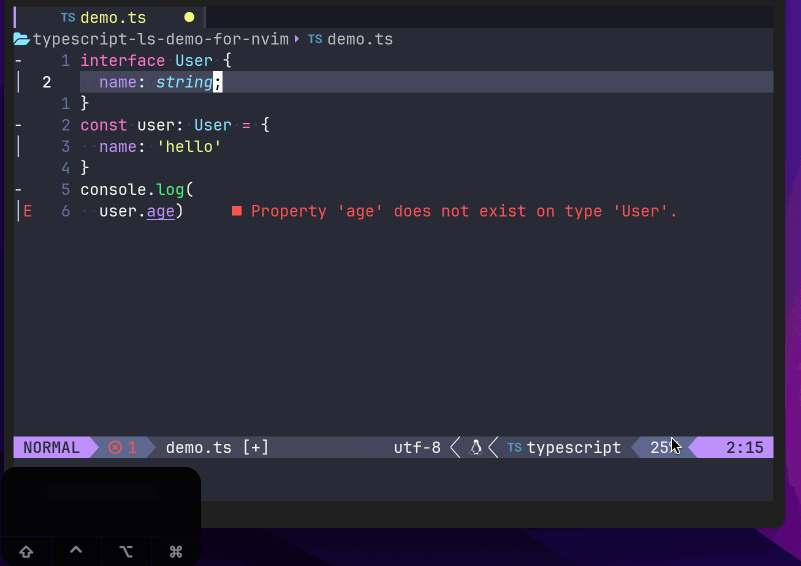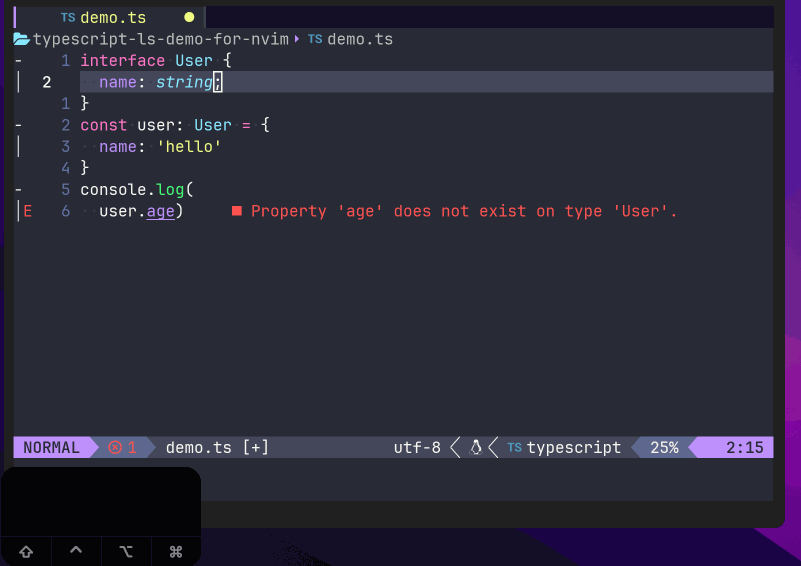
亦或是,在错误代码的地方,调用lua vim.lsp.buf.code_action(),来让语言服务器给出一定的建议操作:
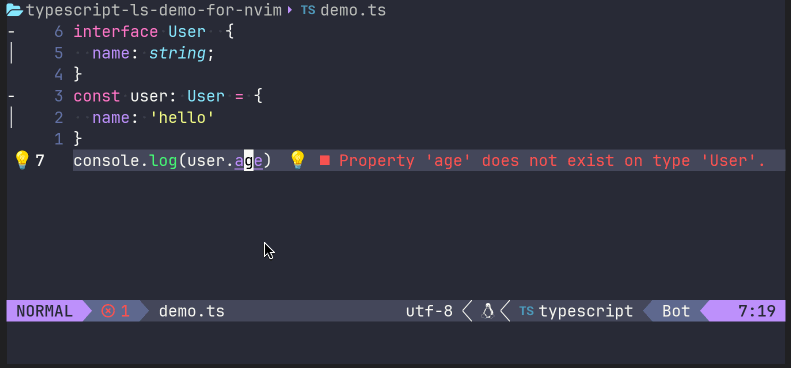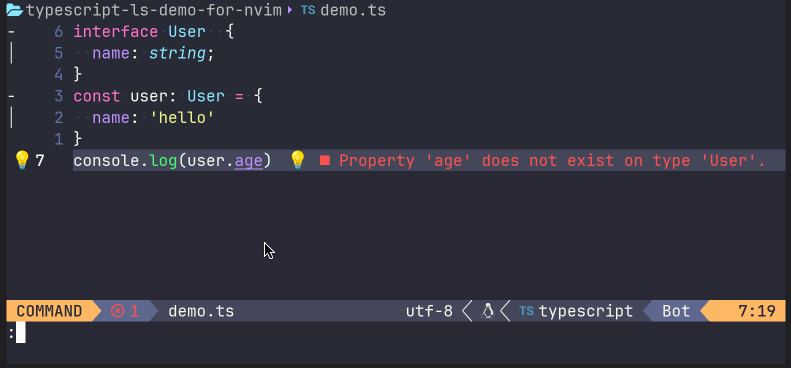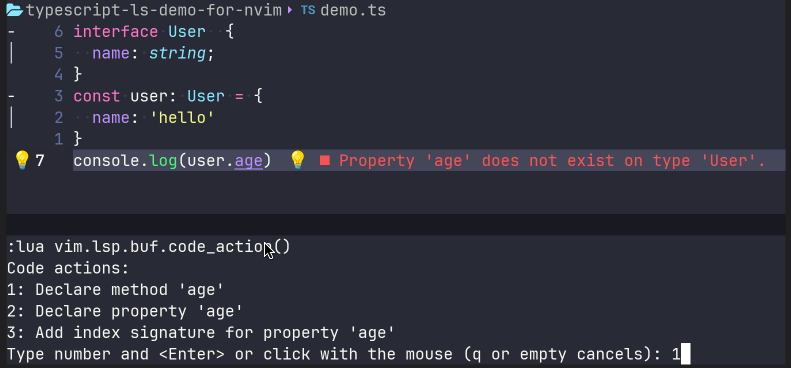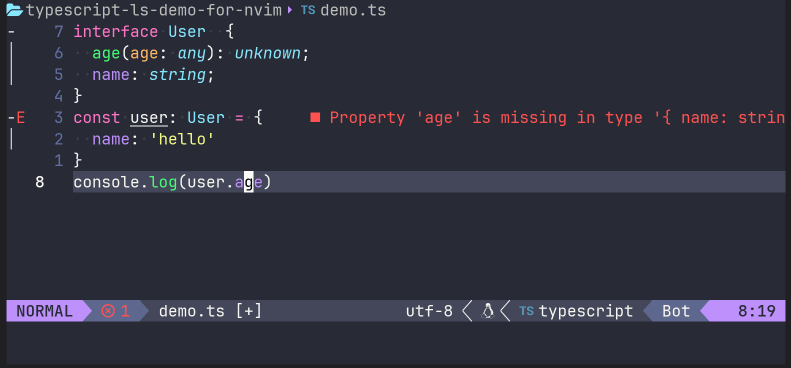
当然,我们不需要每一次想要使用LSP提供的功能的时候都调用命令行方式进行,你可以在setup每一个语言服务之前,添加对事件"LspAttach"的回调,以便在打开代码文件的时候触发该回调,设置对应buffer的keymap。

上面的例子,我们就配置了CTRL+ALT+l(L小写)键来触发代码格式化(format),在我的mac机器上效果如下:
mac机器上CTRL显示为"^“;ALT(meta)键显示为"⌥”。
至于其它的LSP的接口API,例如查看类型定义、查看符号在哪里引用等,我们暂时不进行配置,因为接下来我们将继续介绍一个在基于nvim内置LSP的接口,各种UI、操作更加优雅现代化的插件:nvim-lspsaga。
nvim-lspsaga
使用nvim内置的LSP模块的时候,它的UI展示大家可以看到比较简陋,比如触发code_action的时候,也是在底端普通文本展示,不够沉浸式。而nvim-lspsaga这款插件补齐了nvim原生LSP模块关于用户体验的短板。
安装完成该插件以后,我们就可以通过Lspsaga暴露出的指令来使用经过Lspsaga封装的LSP的接口了。例如,在上面的例子中,我们在一段错误代码上使用命令:lua vim.lsp.buf.code_action(),调用nvim内置的LSP的原生的API来获取代码建议操作:
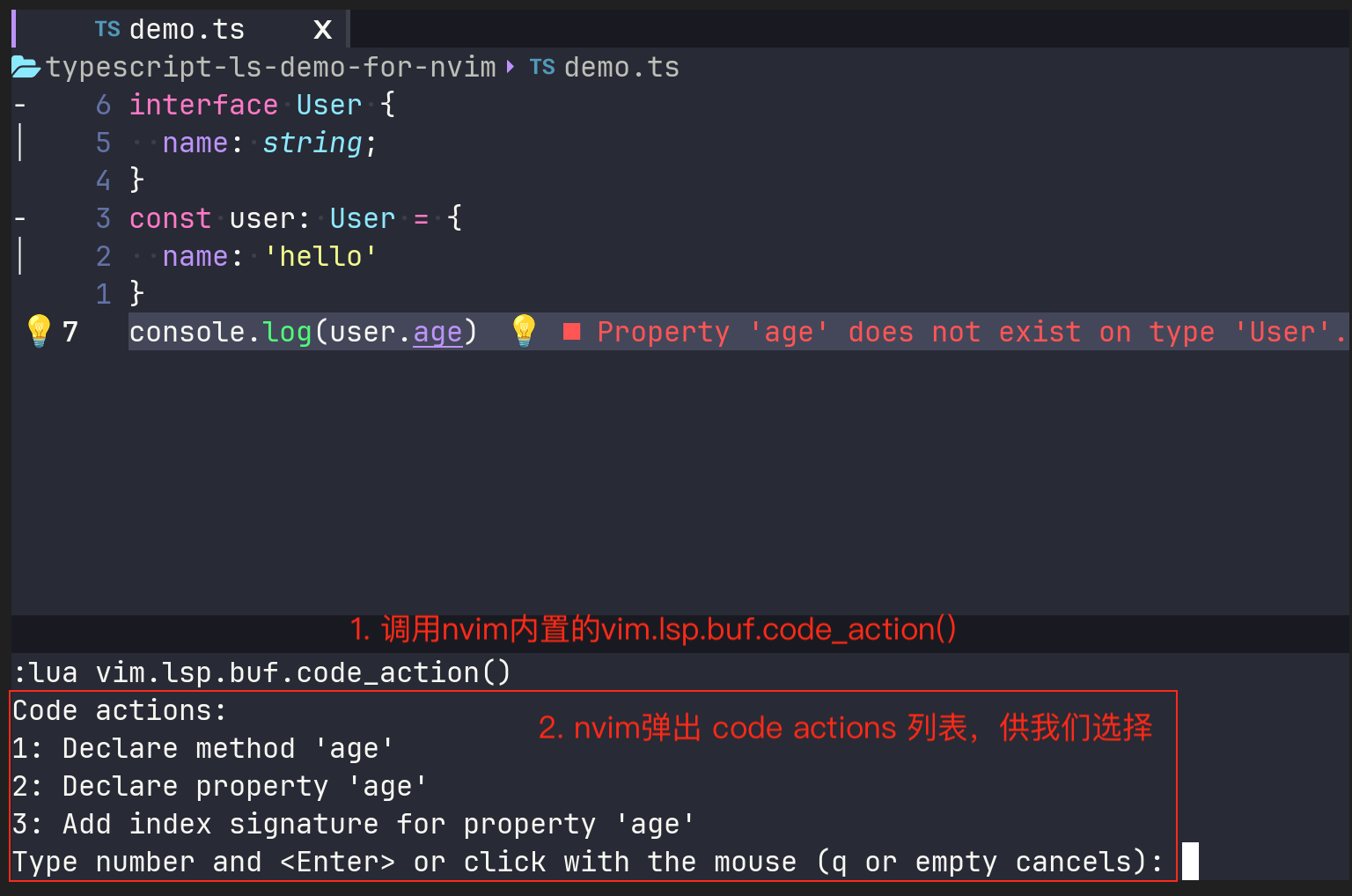
但是,如果我们使用Lspsaga的code_action,就会发现一个非常舒服的UI:
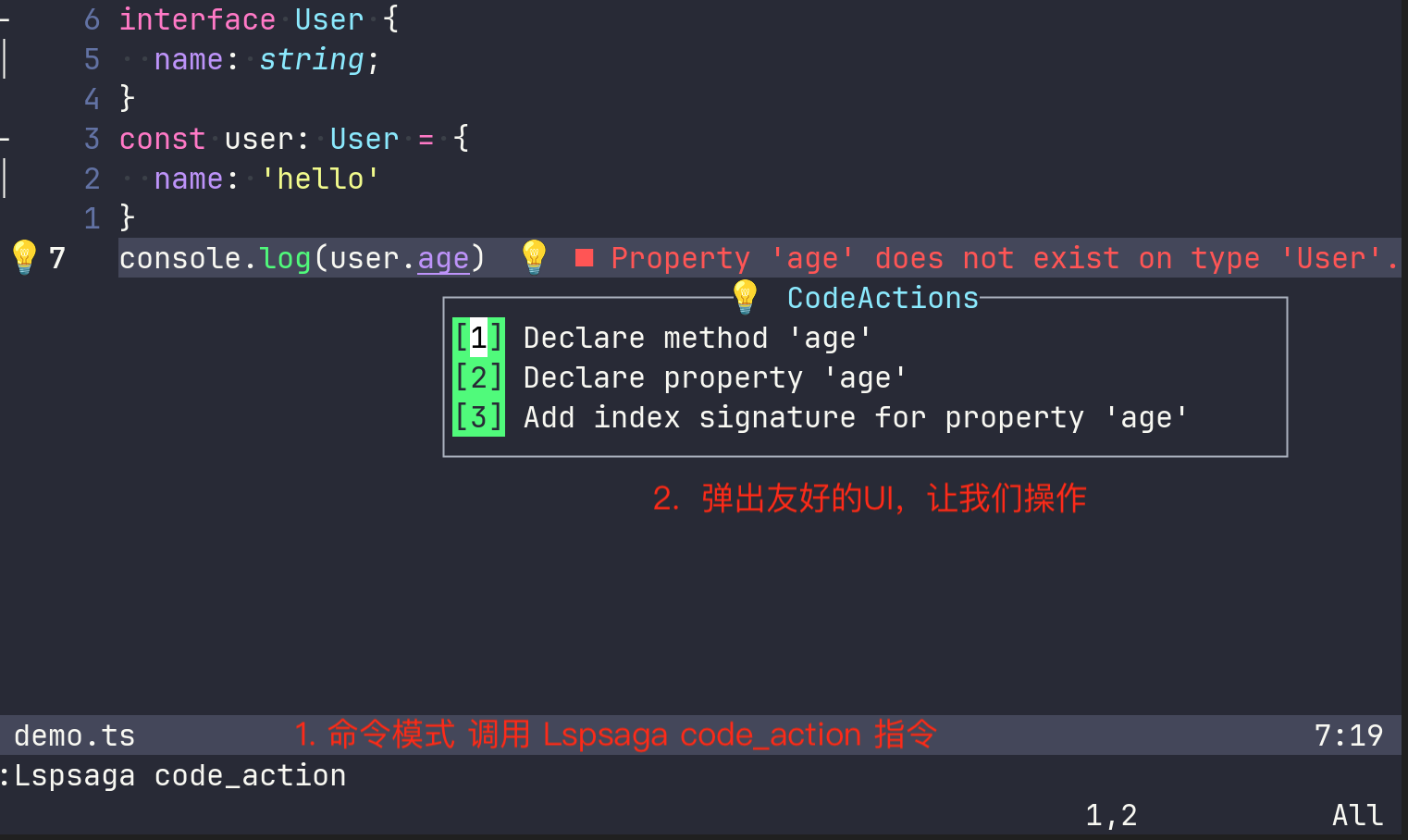
除此之外,还有像是查看引用:Lspsaga peek_definition等指令供我们使用,这里就不再演示了,读者完成配置以后,可以自行测试。
另外需要注意的是Lspsaga官方提到了nvim-treesitter是可选的依赖,但事实体验上强烈要求安装nvim-treesitter插件,因为像是用于像是代码大纲的"Lspsaga outlint"命令,或是用于查看代码定义的"Lspsaga peek_definition"命令,都会用到treesitter来进行代码块的解析处理,如果不安装会有报错的情况,影响体验。所以,接下来我们再补充介绍一下nvim-treesitter插件。
nvim-treesitter
在介绍nvim-treesitter之前,我们需要了解tree-sitter这个工具。tree-sitter是一款主要通过Rust编写的跨平台的代码解析器生成工具和增量解析库,它可以为源代码文件构建一颗具体语法树。也就是说,它能从源代码中解析出代码结构,比如哪些是变量,哪些是方法,基本代码结构是怎样的。正式由于该能力,支持代码高亮的编辑器基本上都会直接或间接使用到该工具。而nvim-treesitter则是tree-sitter和nvim之前的封装桥接插件。在nvim中要想体验代码高亮,基本上都离不开该插件。
当然,nvim-treesitter并不严格属于LSP体系。它的主要作用是对代码解析出各种符号、结构,以便呈现nvim中文本的高亮。但是,我们使用nvim想要搭建一套趁手的代码编写环境,基本上是离不开nvim-treesitter的,像上面的nvim-lspsaga在使用的过程中,也是会调用nvim-treesitter相关的API来提升插件体验,所以也一并安装吧。
对于nvim-treesitter,它同样将不同的语言进行了解耦拆分。你可以通过setup配置,来定义哪些文件要高亮。需要注意的是,配置对应语言启用高亮,nvim-treesitter会在第一次加载的时候,在你的机器上通过C/C++编译工具链编译对应语言的parser,并存放到插件所在目录/parser目录下,读者在安装遍以后,可以自行查看。
nvim的LSP、lspconfig与lspsaga之间的关系
看到这里,可能有的小伙伴对目前介绍的nvim内置的LSP模块、nvim-lspconfig与nvim-lspsaga插件的关系还有些疑惑,这里我们用一个关系图做一个简单的总结:
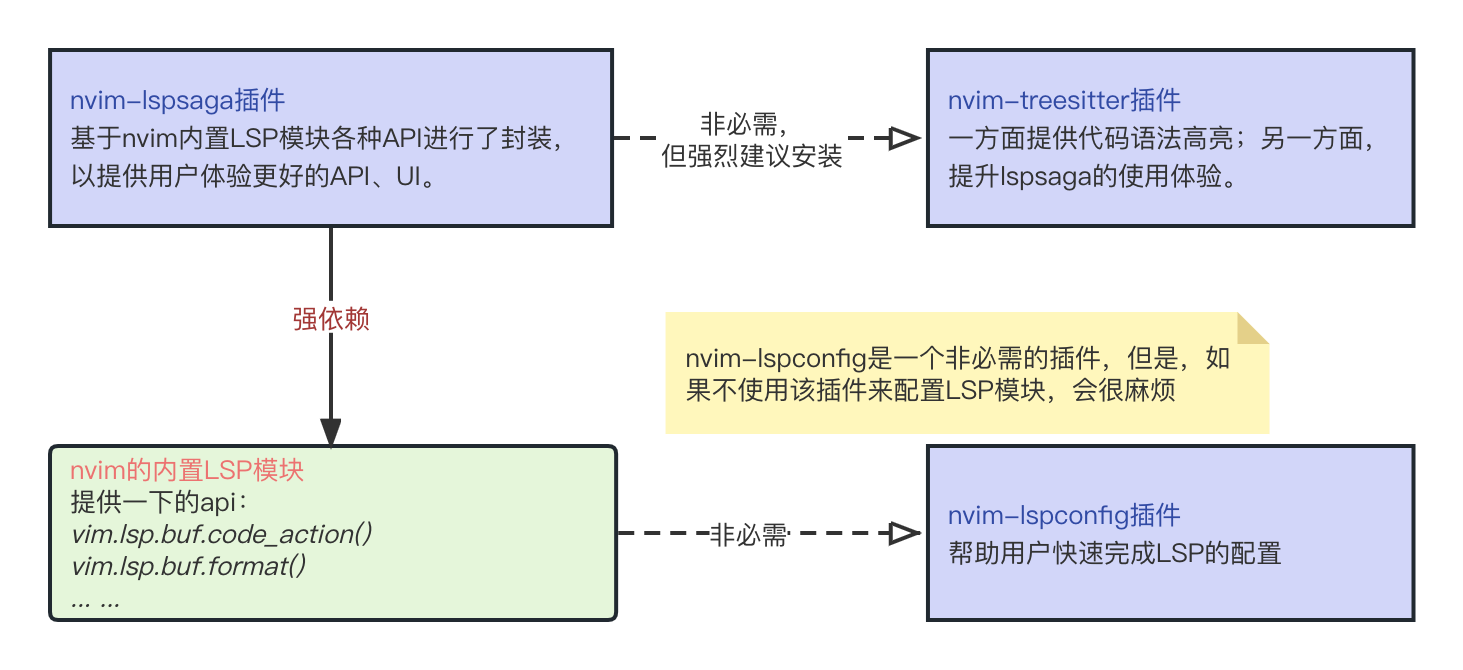
首先,nvim内置的LSP模块提供了诸如vim.lsp.buf.format()、vim.lsp.buf.code_action()等API,只要你配置好了对应编程语言的语言服务模块,那么调用这些指令就能看到效果。
但是,配置语言服务如果仅使用nvim原生的方式是比较复杂的,于是nvim官方提供了一个插件nvim-lspconfig,来帮助用户以更加简单快捷的方式来配置语言服务。
最后,由于nvim内置的LSP模块提供的接口在调用后的交互等比较简陋,于是有了nvim-lspsaga这个插件,实际上它的底层也是调用的nvim内置的vim.lsp相关的接口获得数据,只是经过封装以用户体验更好的方式展示了出来,同时,使用nvim-lspsaga的时候,最好也安装好了nvim-treesitter,一方面它可以完成代码的语法高亮,另一方面,lspsaga也会用到该插件的能力提升各种代码解析的体验。
有了上述关系,我们一般都不配置快捷键来映射vim.lsp.buf.code_actions()等这些原生API调用,而是安装lspsaga插件,然后使用经过Lspsaga封装后的Lspsaga code_action等指令调用。
PS:目前似乎lspsaga不支持format(也许我没找到),只有格式化代码还需要使用原生的
vim.lsp.buf.format()调用,在LspAttach里面的回调中绑定keymap。
null-ls.nvim
Github地址:null-ls.nvim
在内建LSP、lspconfig以及lspsaga的加持下,nvim已经具备了支持LSP能力的,且用户体验较好的准IDE了。然而,有这样一个场景还没有涵盖到,那就是在语法已经正确的情况下进行代码的处理,包括prettier格式化、eslint代码处理。具体来讲,比如下面这样一段代码:
1 | |
上述这段代码,**从TypeScript语法规范的角度来看是没有问题的,完全能够通过TS的类型检查。**然而,上面的代码有两个问题:
- 使用
var来声明一个变量,这已经是不推荐的变量声明方式了; name字段的格式化不正确,一般我们使用2个或4个空格来对应一个Tab。
基于上述的问题,不难理解,语言服务通常只专注于代码本身的类型检查、代码编译是否正确,它一般不关注代码是否处于最佳实践,比如代码格式规范、代码使用规范等。为了补齐这块,null-ls被推出。该插件主页提到了这个插件创造出来的动机:
Neovim doesn’t provide a way for non-LSP sources to hook into its LSP client. null-ls is an attempt to bridge that gap and simplify the process of creating, sharing, and setting up LSP sources using pure Lua.
Neovim没有提供一种非LSP源连接到其LSP客户端的方式。null-ls试图弥合这个差距,简化使用纯Lua创建、共享和设置LSP源的过程。
这里面需要解读几点:
-
什么叫“非LSP源”呢?像是prettier、eslint,它们本身需要对程序代码进行结构、类型解析,然而它们又不关注代码的类型检查等,这类就属于“非LSP源”;
-
什么叫“使用纯Lua创建、共享和设置LSP源的过程”呢?还记得前面的TS语言服务、lua语言服务吗,他们都是实现了LSP协议的语言服务,各自分别用js和lua语言编写的,需要外部进程启动。而null-ls希望能够用lua来编写,构造一个类似支持在nvim内部运行语言服务的框架(虽然目前 prettier、eslint还是外部安装启动的 😛)。同时,使用null-ls还可以通过编写lua代码,注册自己想要解析的文件进行文本处理:null-ls.nvim#parsing-buffer-content。
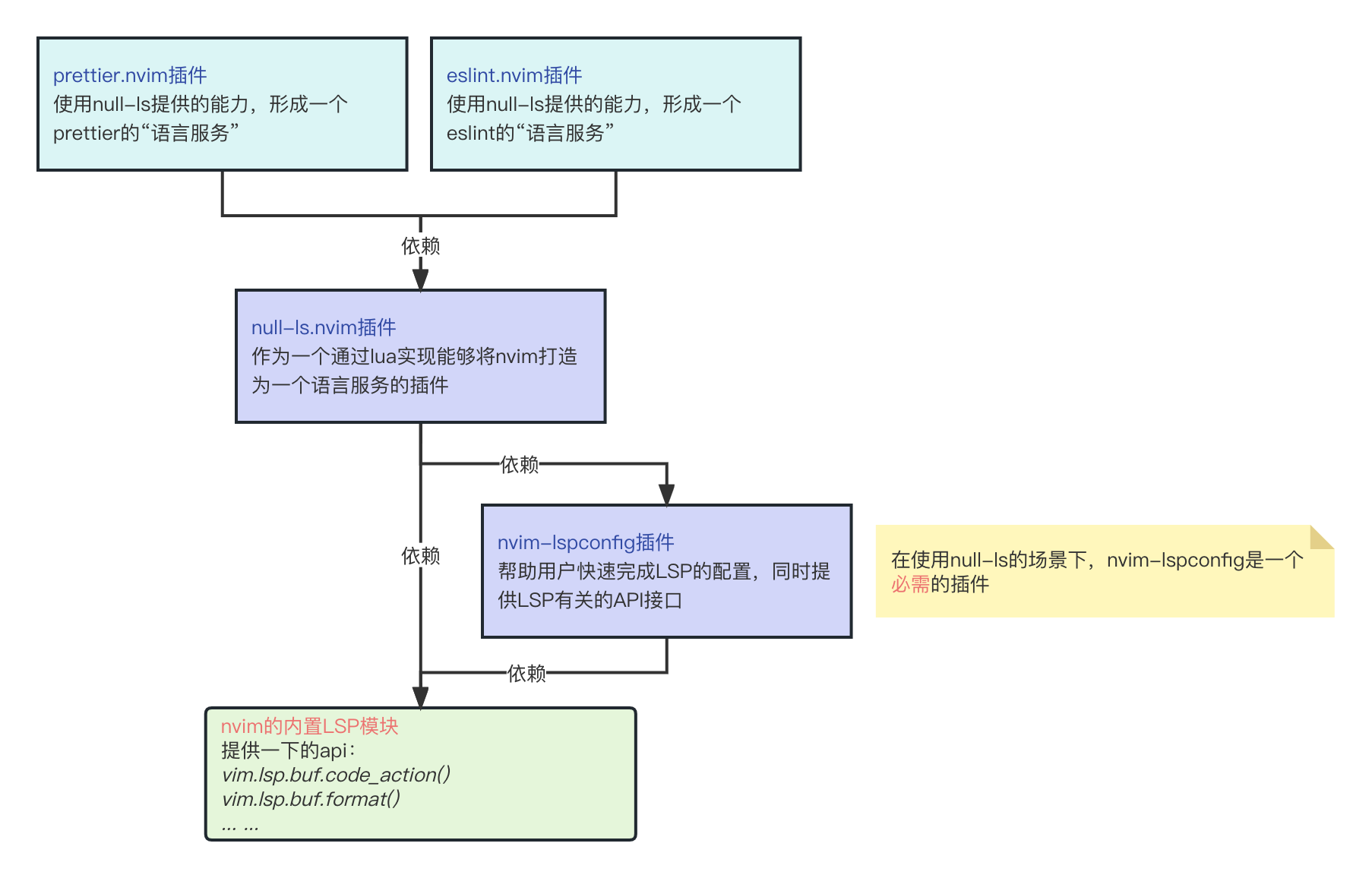
了解了null-ls的作用以后,我们简单总结下如何使用基于null-ls的prettier、eslint来处理代码。
我们首先需要安装null-ls插件,不过它依赖lspconfig插件,内部用到了nvim的LSP的相关接口以及lspconfig暴露的进行LSP处理的接口,这点我们不深入源码了。
然后,我们需要安装prettier.nvim和eslint.nvim和插件。这两个插件都是利用了null-ls的关于LSP的接口,来和外部安装的prettier、eslint命令行工具进行调用。用一个图来解释如下:
nvim的代码补全
众所周知,一个合格的代码编辑器,除了能够完成语法检测以外,还有一个很重要的功能就是代码补全。
在继续介绍下面的代码补全相关插件之前,让我们首先思考一下,代码补全需要哪些上下文才能完成。首先,我们需要有整个文本内容解析的文本片段;如果是一个工程,那么我们应该有一个工程下所有文件内容的解析片段;除了文本片段以外,我们还需要具备代码语言的解析能力,包括不限于语法解析,语法类型等,因为当我编写一个number类型变量的时候,你不能给我提示或补全为另一个string变量。在LSP出现以前,很多IDE就具备了补全的能力,它们都会有自己的文本解析引擎,分析代码结构、语法树;同样的,在LSP出现以后,LSP模块可以给我们提供代码级语法级的解析内容来增强补全片段内容。
如果使用nvim内置的LSP配合nvim-lspconfig,nvim是不提供代码补全能力的,仅有类型、语法检查、各种代码定义与实现的查看与跳转等功能。为了让nvim支持代码补全,我们需要有一套补全的机制来完成这个任务,而nvim-cmp可以很好的完成这个任务。
nvim-cmp简介
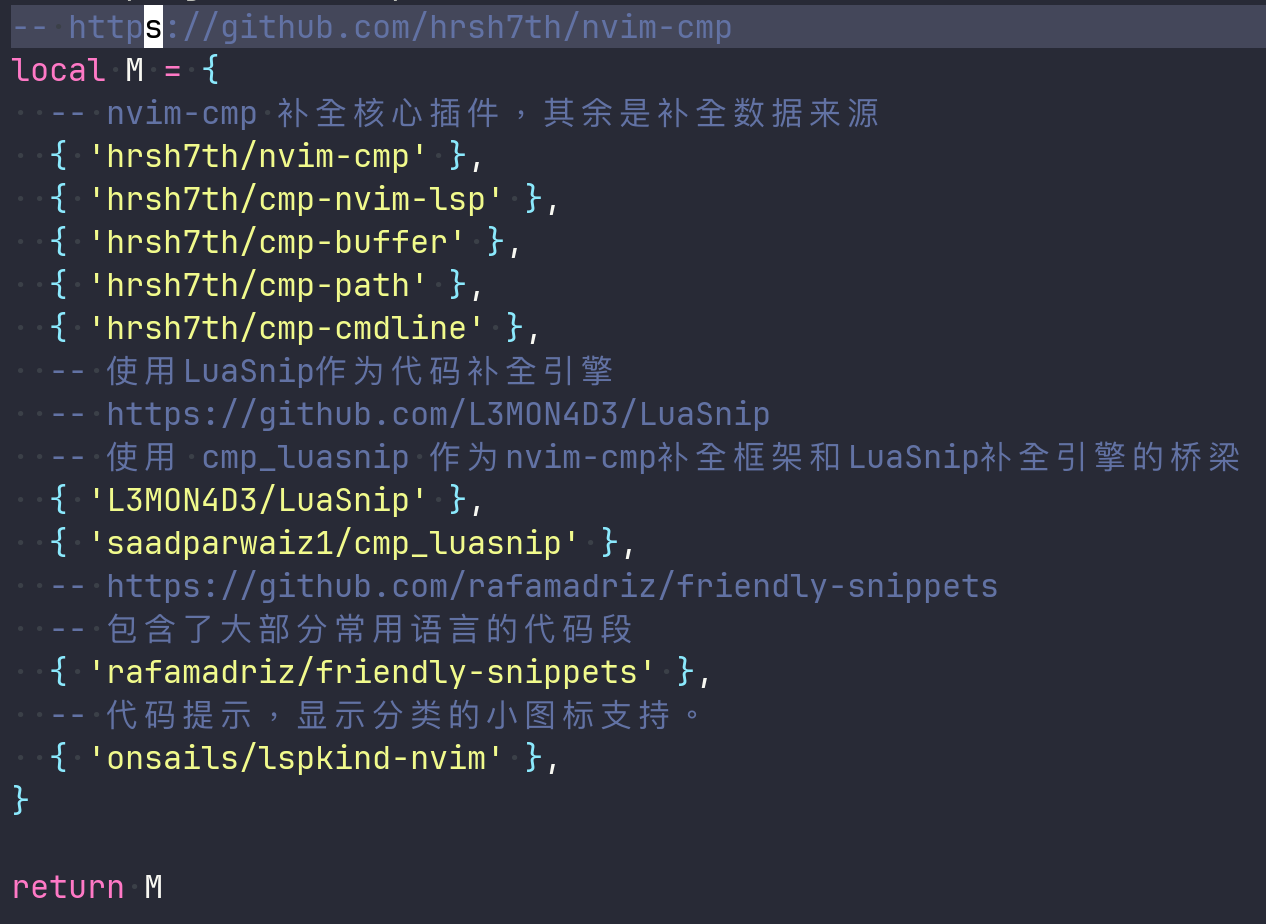
nvim-cmp是一款通过lua编写的,nvim中的代码补全引擎框架插件。代码补全,离不开snippet(片段),因为最终补全的时候,引擎会将一个又一个的代码片段提供出来让用户选择使用,进而补全当前的代码。当然,这些snippet不是平白无故出现的,它们一般从某些地方搜集而来,而这些搜集的来源,就是片段源。片段源可以有很多,比如代码语法树中的token,命令行支持的指令,各种git的指令,文件系统路径等。nvim-cmp以解耦思想进行设计,将各种不同的片段获取来源分离在了不同的插件中。通常,安装nvim-cmp的时候,都会安装如下的几个插件:
1 | |
-
cmp-nvim-lsp是来源于语言服务分析整个工程得到的片段源,所以它依赖nvim-lspconfig;
-
cmp-buffer则是当前打开的文件内容通过文本解析得到的片段源;
-
cmp-path则是通过对系统文件路径得到的片段源,譬如当你键入"/"的时候,可以展示可用的文件路径供你补全;
-
cmp-cmdline是通过解析命令行得到的源;
-
最后的nvim-cmp则是核心引擎框架。
除上述以外,还有其他的来源或实现,读者可以查看这里来获得已知的源:List of sources · hrsh7th/nvim-cmp Wiki (github.com)。
此外,读者还会发现,在nvim-cmp的官方配置的示例中,除了上述的引擎和源以外,还有如下插件需要安装:
1 | |
上述有4对,都是一个cmp-*的插件搭配一个对应的插件,使用者任选一套安装。那么这一对插件的作用是什么呢?
实际上,nvim-cmp不负责具体的补全操作,它的核心能力是根据各种源搜集供补全的文本片段,并提供了对这些片段的访问能力。而上述的一套插件,以'L3MON4D3/LuaSnip'配合'saadparwaiz1/cmp_luasnip'为例,LuaSnip是核心的代码补全操作引擎插件,他提供补全过程中UI操作等能力;而cmp_luasnip则是作为了nvim-cmp和LuaSnip之间的桥梁,就像适配器一样。这个架构如下:
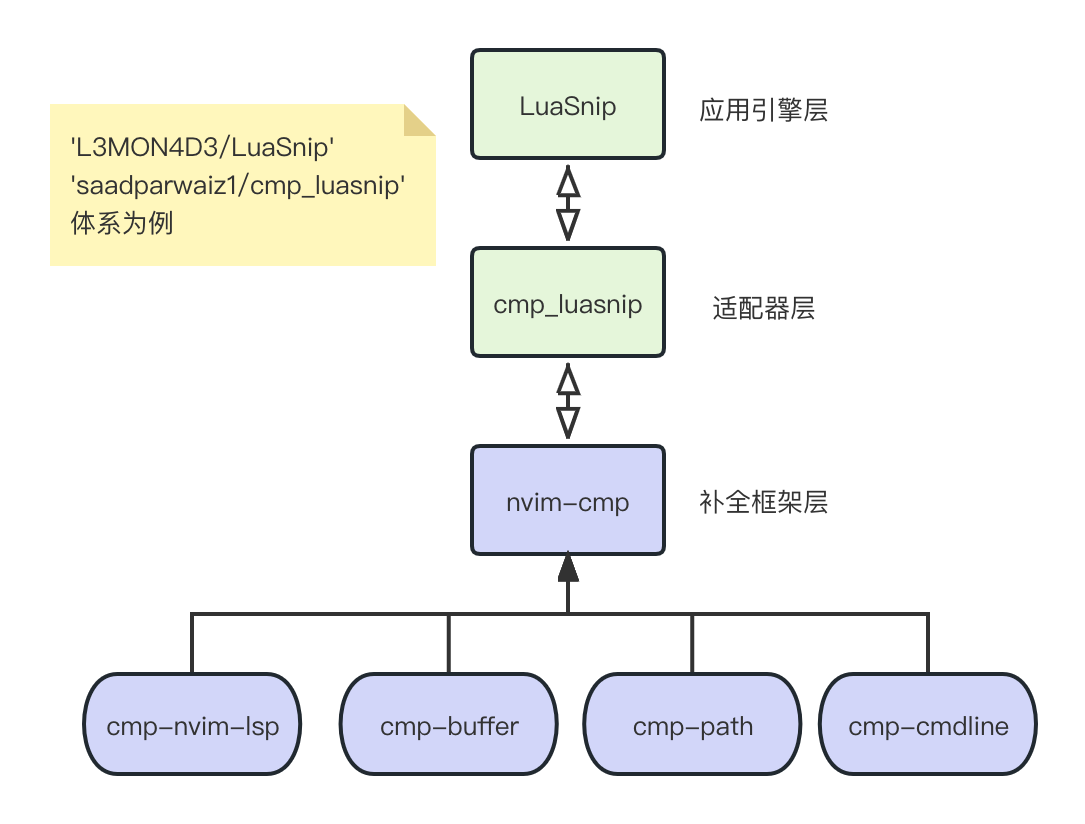
此外,我们一般还会添加两个插件'rafamadriz/friendly-snippets'和'onsails/lspkind-nvim'来扩展补全体验。前者会提供我们编写代码的时候,大多数常见代码的snippet(就像trycatch等),这块的加载下面单独介绍;而后者则是在代码补全的后选项添加图标。
nvim-cmp的基础使用
在介绍了基于nvim-cmp的代码补全体系以后,接下来我们简单介绍下其基本的使用,当然笔者还是使用lazy.nvim管理插件。使用nvim-cmp体系的同样分为两步:1、插件安装;2、在合适的时机setup插件。
按照前面插件的介绍,我们安装如下的插件:
对于nvim-cmp的setup,配置如下:

主要分为4个字段:
- snippet字段:
1 | |
该部分主要指定snippet的引擎,配置方式按照上述即可。
- sources字段:
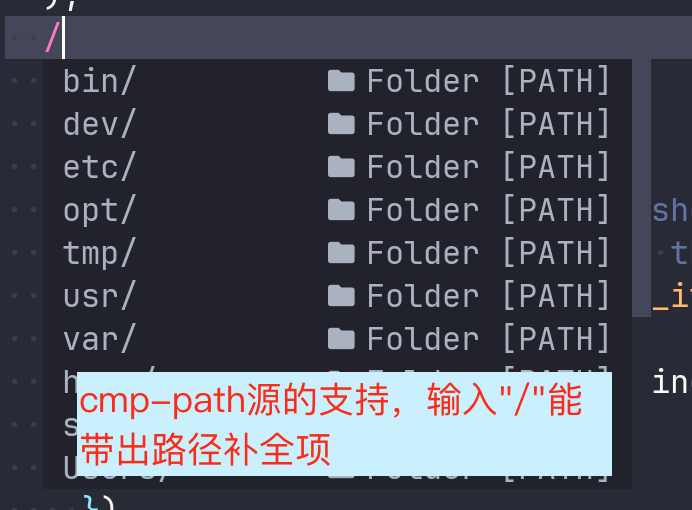
1 | |
该字段主要用于配置补全的源,这里需要和前面的cmp补全源插件一一对应。例如,当配置了cmp-path的path源的时候,键入“/”就能看到候选的路径补全项:
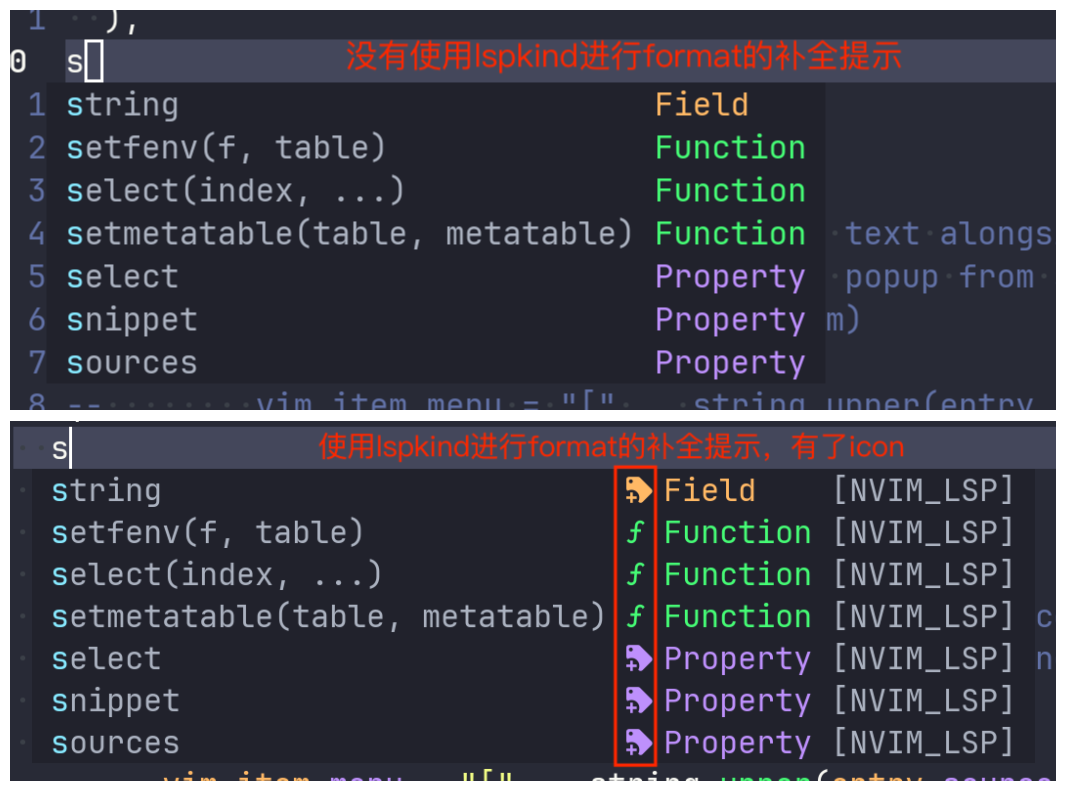
- formatting字段:
1 | |
这里主要是依赖插件'onsails/lspkind-nvim',代码补全时,会展示对应来源的图标:
- mapping:
1 | |
mapping主要是按键绑定,这里就不赘述,看配置以及描述应该不难理解。
加载friendly-snippets
当然,上述的流程没有涉及到如何配置加载friendly-snippets,想要让LuaSnip(我们本例中使用的补全引擎)能够加载到各种外部的已经编写好的snippet,需要我们在对nvim-cmp进行setup的时候,同时通过luasnip的loader,来加载各种自定义的snippet。于是,我们最好在nvim-cmp的setup位置同时调用如下的代码:
1 | |
整体来说如下:
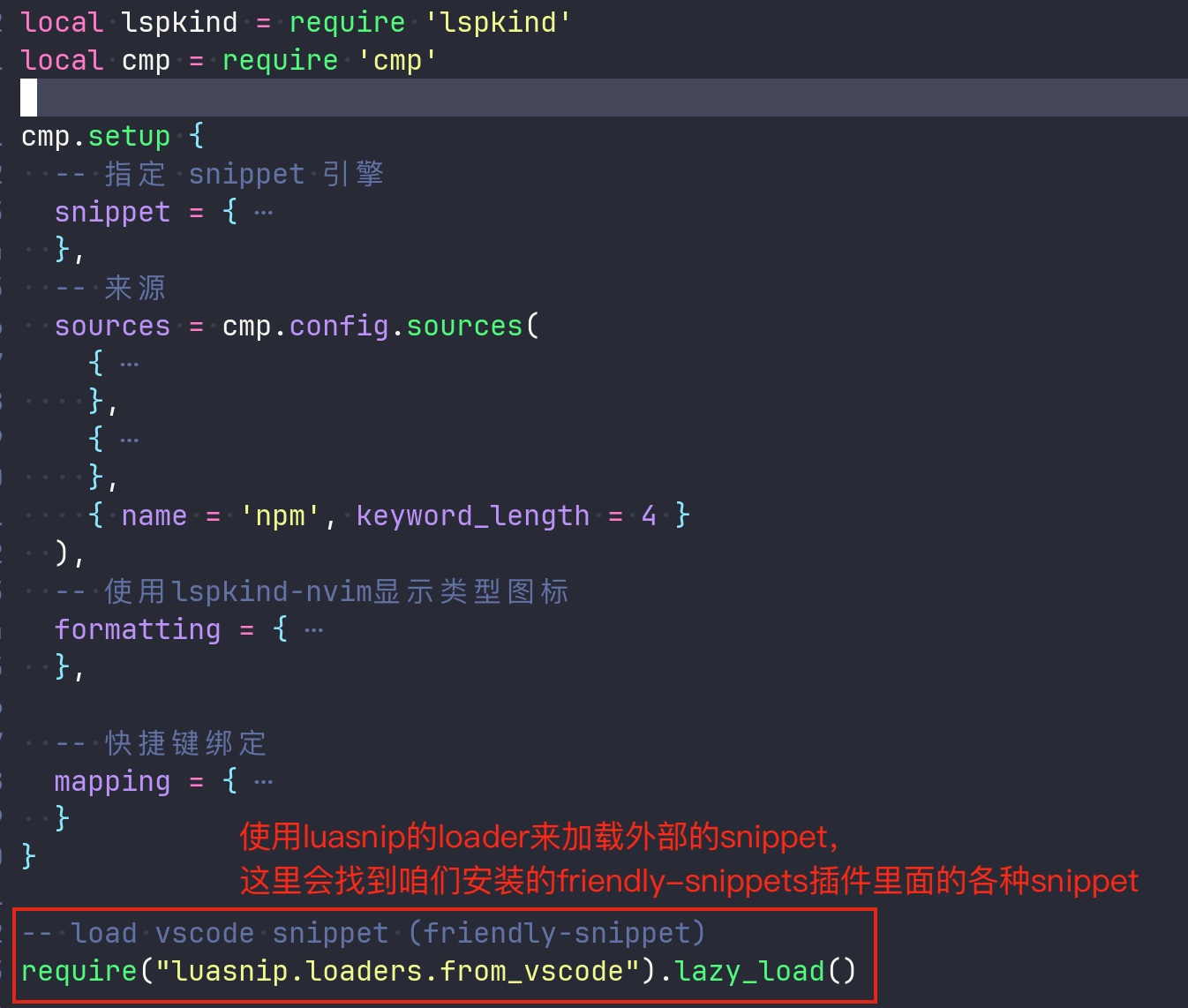
也就是说,在我们使用luasnip引擎的场景下,我们会调用上述的api来完成对外部snippets的加载工作。这里lazy_load没有填写任何的参数,则会使用runtimepath下进行寻找,而我们的插件就能通过runtimepath进行访问到,所以会把friendly-snippets插件目录下的的snippets搜并加载到。
总结
nvim中的代码编写体验主要由两块构成,一部分是语法检查,各种代码定义、引用跳转,另一部分则是代码补全相关,而这两方面算是nvim的配置中较为复杂的点了。本文针对这两个复杂点,从模块架构的角度,介绍了nvim中的内建LSP体系和代码补全体系。对于内建的LSP体系,主要涉及到了nvim-lspconfig、nvim-lspsaga、nvim-treesitter以及null-ls插件,本文也对他们的关系进行简单的梳理;对于代码补全,本文则介绍了基于nvim-cmp的代码补全架构。希望本文能够帮助读者对这两块内容所涉及到的插件和配置有一个大体的认识,从而在nvim开发环境的搭建过程能够做到游刃有余。
当然,对于nvim中的代码开发体验还有关于代码调试会涉及到DAP,它和LSP的架构其实是比较像的,这块内容会在后面的文章关于'nvim-dap'插件体系的代码调试进行更近一步的介绍。