写在前面
笔者前段时间开启了一个新的系列《Wgpu图文详解》,在编写的过程中,发现使用wgpu只是应用层面的内容。要想很好的介绍wgpu,不得不将图形学中的一些理论知识进行讲解。但是放在《Wgpu图文详解》这个系列里又有点喧宾夺主之意,所以决定单独用另一个系列来放置关于图形学的一些内容。另外,本系列的内容并不是按照某种顺序来编写的,而是想到哪些要点就介绍一些,算是带有科普性质的知识笔记。
笔者并非图形学专业人士,只是将目前理解到的一些内容整理成文,如有内容上的问题,还请读者指出。
本文内容主要为概念介绍,所以不会有代码产生。
三维世界基础
我们都知道,两点组成一直线,三线(三点)组成一平面。所以,假设在三维空间中有这样三个点:(0, 1, 0)、(-1, 0, 0)、(1, 0, 0),通过简单的思考,我们知道它们可以组成一个没有厚度的三角形,当然,我们可以使用更多的点组成更多的面,来创造一个更加立体的物体:
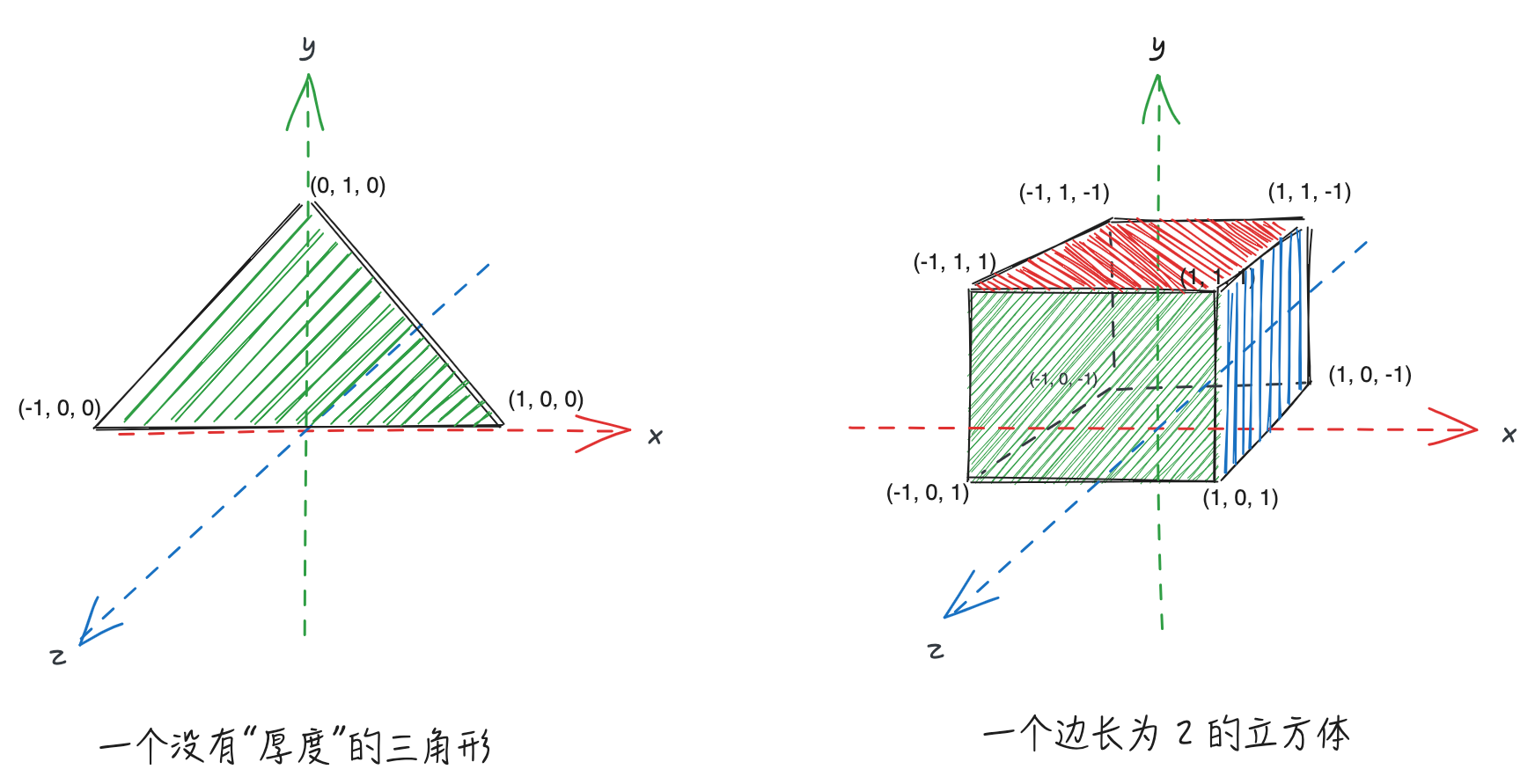
对于一个三维空间的物体,我们一般分为两个阶段来“感知”它。
第一阶段是“创造”这个物体。我们首先在空间的某处定义好一些“顶点”;然后,通过将这些“顶点”两两直线相连,我们会得到一个物体的框架;最后,我们给框架上的每一面“糊”上一层“纸”,就得到了一个不透明的立体物体。
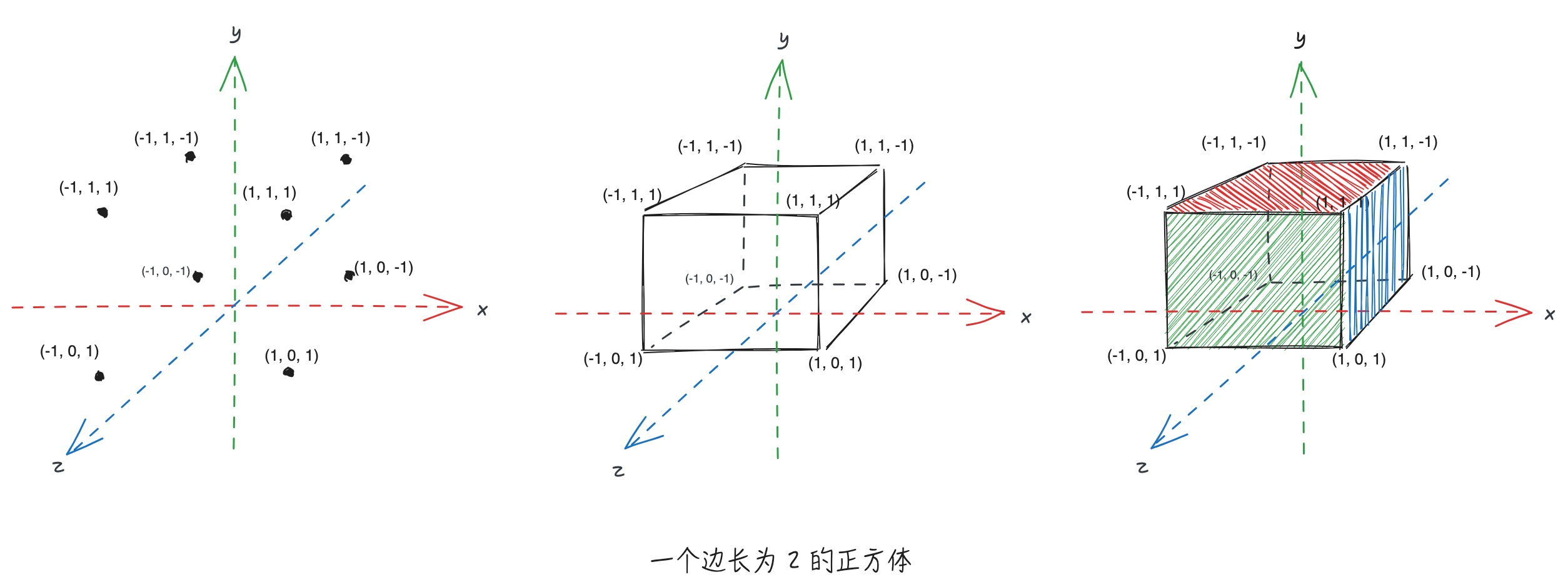
第二阶段则是“观察”这物体。在第一阶段,我们仅仅是将一个三维物体创造了出来,它存在于空间的某处。为了让我们感知到它的存在,我们会用眼睛从某些角度去看它,或使用一台摄像机将它拍摄并呈现在一张照片上。但无论哪种方式,我们会发现我们都将一个空间中三维的物体“投射”一个“面”上,即将三维物体“降维”到了二维面上。
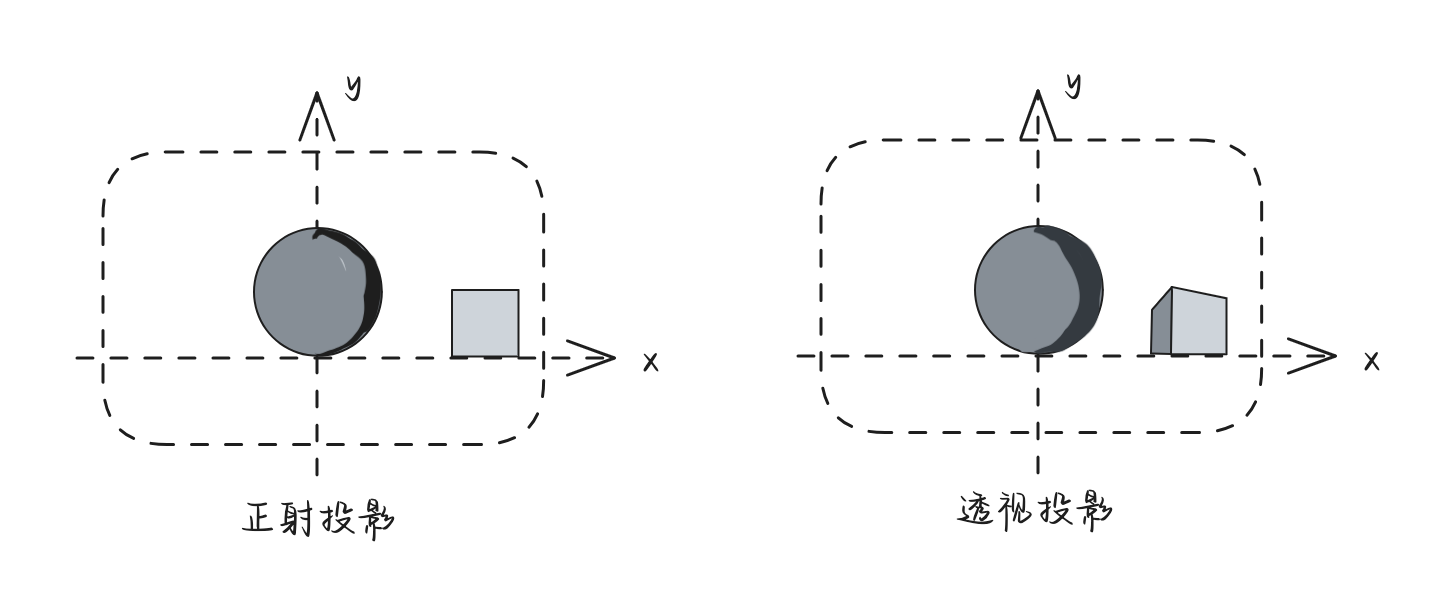
当然,将三维物体投影到二维平面上,一般有两种投影方式:正射投影、透视投影,二者最大的区别在于透视投影需要考虑近大远小的成像机制。例如,上图的立方体场景下,我们在站在z轴上俯看立方,正射投影和透视投影会出现不同的效果:
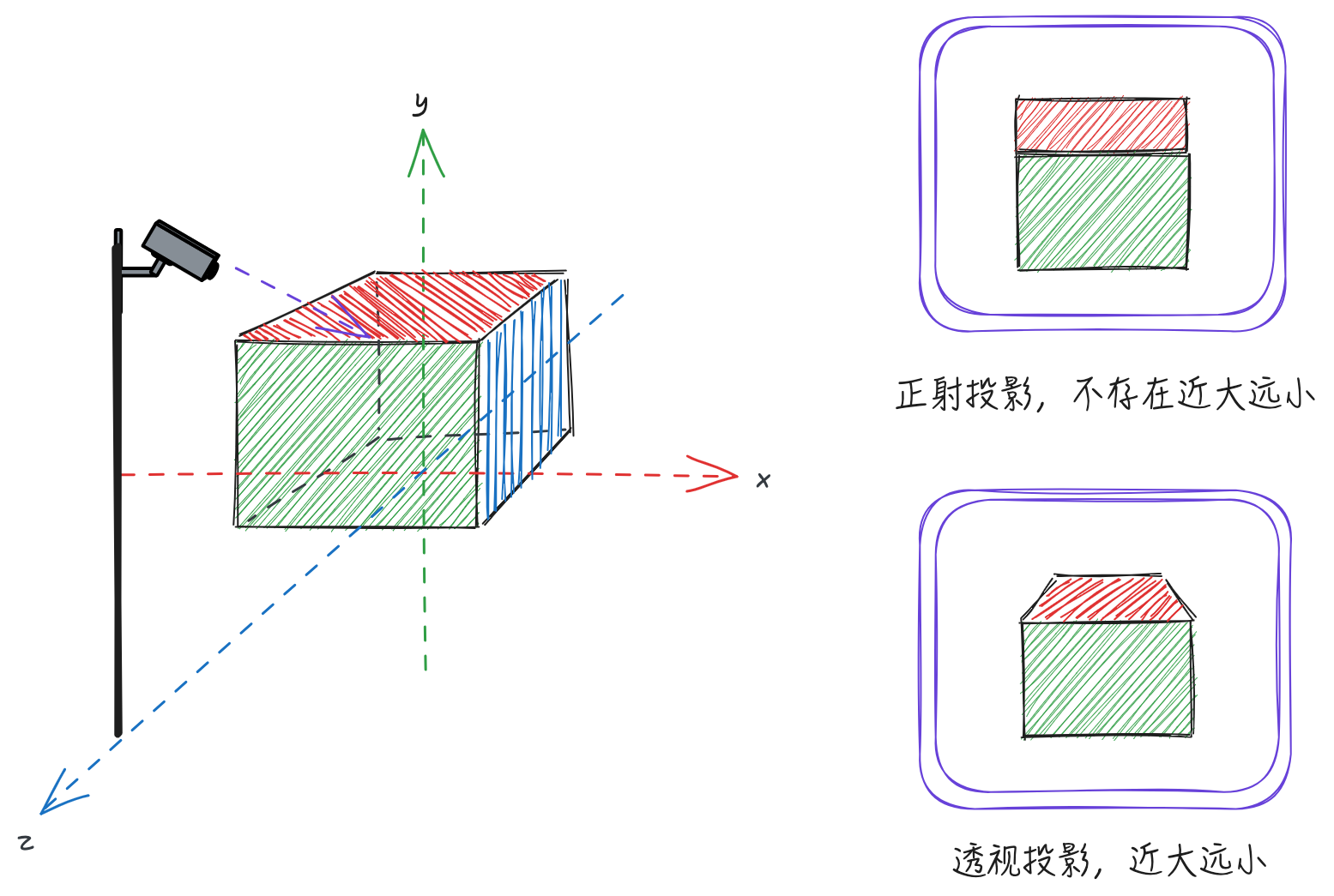
从上图可以看出,透视投影明显是最符合我们通常认知的投影方式。对于三维世界有了基本的认识以后,让我们接下开始对图形学的一些内容进行介绍。
图形学的要素
在上节中,我们简单介绍了在现实的三维世界中如何构造并观察到一个三维物体。在计算机图形学中其实也并没有完全的跳出这个过程。在计算机图形学中同样会有点、线、面,以及最终要呈现到屏幕上的“投影”。我们将从本节开始,深入浅出计算机图形学的一些重要概念以及它们的核心作用。
顶点 vertex
什么是顶点?读者初识“顶点”这个词的时候,可能会觉得“顶点”就是上面三维物体在构建过程的第一步中,我们进行定义的各个“点”。这样的理解对但不完全对,因为几何物体上的各个点是狭义上的顶点,它们仅仅表示三维空间中的一些位置。
而计算机图形学中的顶点vertex,则是一个包含有更多内容的数据合集,包括不限于该点的:位置坐标、颜色信息等(为了不然读者产生过多的疑惑,我们先只提较为理解两个属性)。也就说,几何中的顶点几乎等同于位置坐标,而计算机图形学中的顶点,除了位置坐标以外,还可以包含该点的颜色等其他信息。
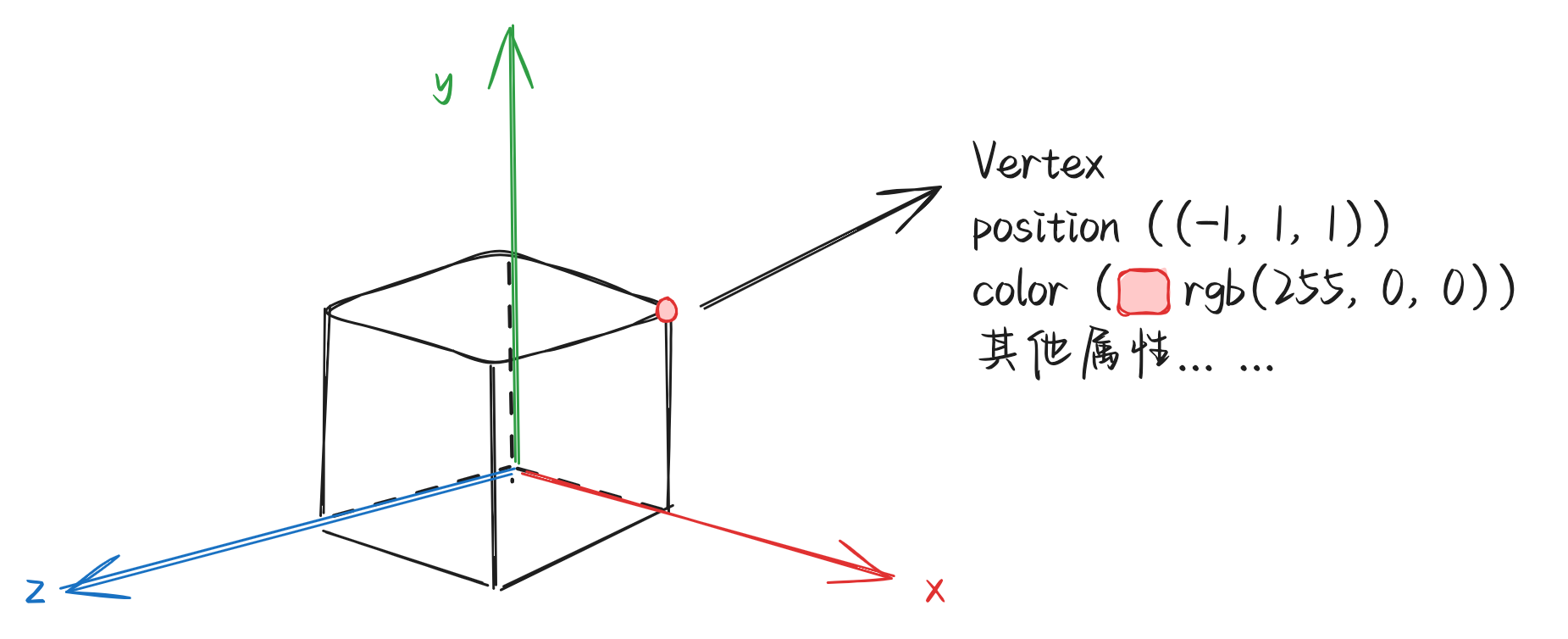
读者一定要记住,从现在开始,只要谈到了“顶点”,都指的是包含位置、颜色以及其他额外信息的整个顶点数据,如果仅仅是描述位置,我们一定使用全称:“顶点位置”。
顶点包含颜色数据的意义是什么?笔者在第一次接触计算机图形学的时候,能够很自然的理解顶点包含位置坐标数据,但是对于包含颜色信息(甚至是法线信息等)百思不得其解,直到后来了解的越来越多以后,才渐渐的理解了这其中的奥妙。当然,这里笔者先卖个关子,等到后续的图元、片元介绍完成以后,再回过头来就能够很好的理解了。
图元 primitive
在计算机图形学中,图元(Primitives)是构成图像的基本元素,它们是图形渲染过程中最基础的几何形状。图元可以是点、线、多边形(如三角形或四边形)等。
图元装配
要得到图元,我们需要将上一小节介绍的“顶点”作为输入,进行一系列的操作,才能得到图元,这个过程就叫做图元装配。让我们用更加形象的例子来理解这个过程。
假设现在有三个点:(0, 1)、(-1, 0)以及(1, 0)。这三个点可以组成什么图形呢?需要我们用不同的方式来看:
- 点方式(Points):每个顶点都作为一个单独的点来渲染。
- 线方式(Line):连续的两个顶点形成一条线段。
- 三角形方式(Triangles):每三个顶点组成一个三角形。
下图是上述三种方式下,结合上面三个点得到图形结果:
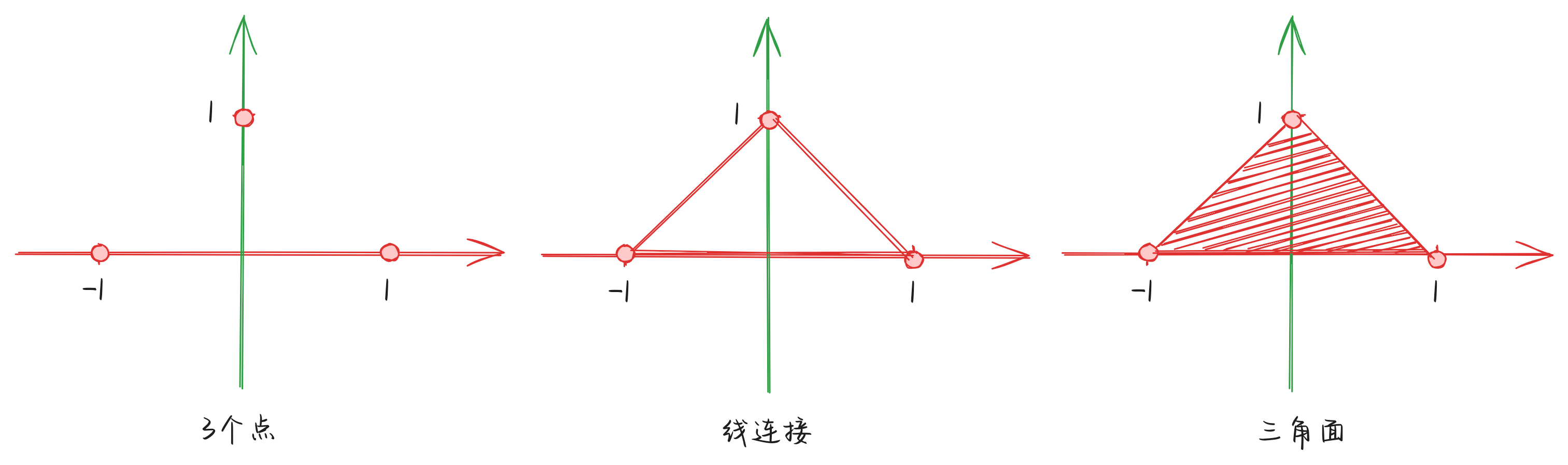
图元装配还远远不止上述提到的三种方式,根据顶点数据的不同,还有其他形式的装配方式
所以,读者现在应该能够理解图元装配的核心逻辑是,将n个顶点通过某种图元装配的方式来得到最终的图形(不同的装配方式往往伴随着不同的算法逻辑)。
当然,在生成图元的时候,还包含了一些操作,不过为了帮助读者更好的理解,我们暂时放一放,后面统一讲解。
片元 fragment
在介绍片元前,我们需要先提到一个操作概念:光栅化。光栅化是将几何数据经过一系列变换后转换为像素,并呈现在显示设备上的过程。我们常见的显示设备是由物理像素点按照一定的宽高值组成一块完整的屏幕。也就是说,屏幕上的像素点不是“连续”的。然而,我们的图像是“连续”的,这就意味着对于几何图形,一条线,特别是非水平非垂直的线,这条线上的每一点我们总是需要通过一定的近似处理,来得到其在屏幕上的物理像素的坐标。
我们以呈现一个三角形为例。假设现在有下图三角形,从几何的角度来看,它的斜边没有任何的异常:
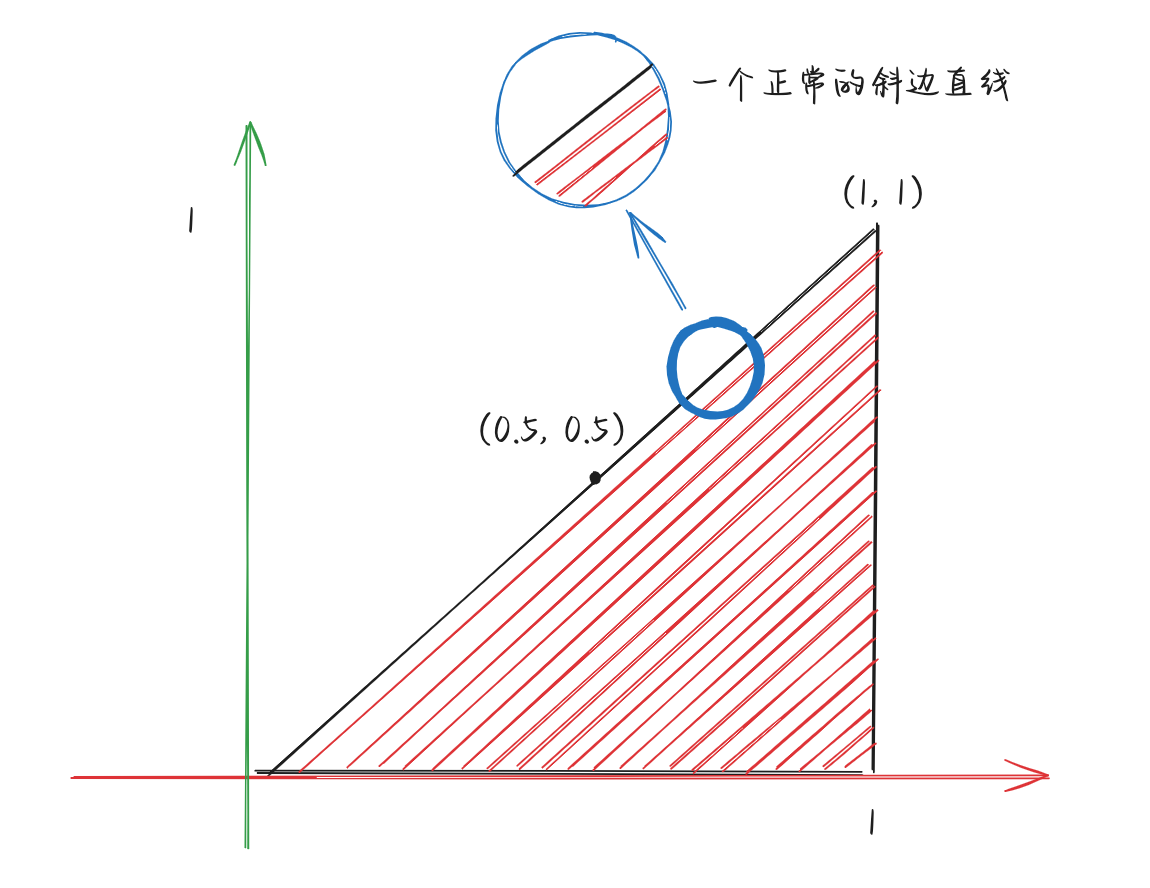 然而,我们的物理设备像素是整数值且有限,假设有一块分辨率为 20x20 的屏幕,为了呈现斜边,我们可能需要按照如下的形式来找到对应的像素点填色:
然而,我们的物理设备像素是整数值且有限,假设有一块分辨率为 20x20 的屏幕,为了呈现斜边,我们可能需要按照如下的形式来找到对应的像素点填色:
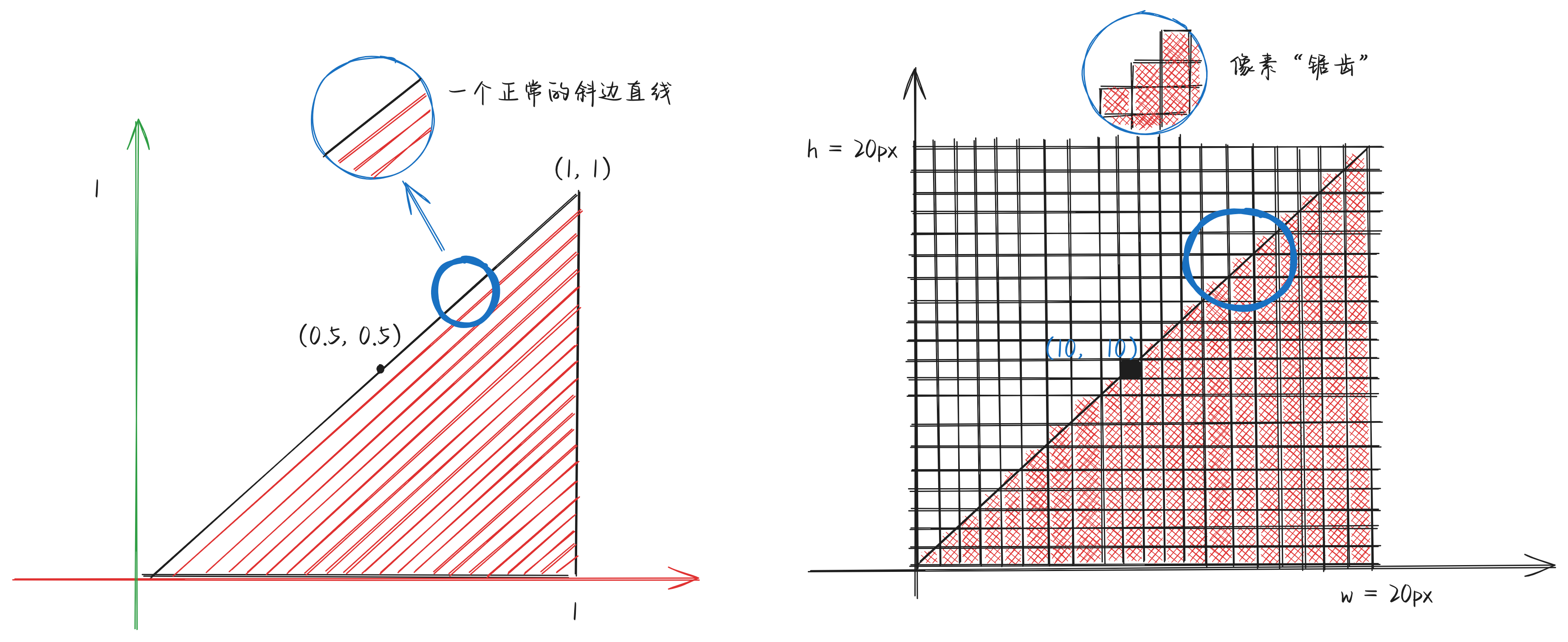
注意看,笔者在几何三角形上选取了1个点,几何坐标为(0.5, 0.5)。在 20x20 的屏幕上,其屏幕坐标为(10, 10)。
光栅化逻辑就是对于几何图形上每一个“点”,在屏幕设备上找到对应的像素点的过程。对于光栅化的实现,就不在本文的讨论范围内了,对于这块感兴趣的同学可以自行查阅相关资料进行深入研究。
简单了解完光栅化后,让我们回到本节的核心:片元fragment。片元实际上就是图元primitive经过光栅化处理后的一个或多个像素大小的样本。在这有两点值得注意:
- 尽管叫做片元,但通常指的是一个或少许多个像素大小的单位。也就是说,图元是一个整体几何图形,经过光栅化会被分解为多个片元。
- 光栅化后得到的片元只是接近像素点,但并不完全等于像素点。片元是与像素相关的、待处理的数据集合,包括颜色、深度、纹理坐标等信息(深度和纹理坐标等先简单理解为一些额外数据,后续会讲解)。这个地方有点类似于前面我们说的,图形学中的顶点,并不是简单的几何的顶点,而是包含有顶点位置、颜色信息等的一个数据集合。
片元并非像素点,它只是接近像素点,所以通常来说,我们还会有一个步骤来对片元进行进一步的处理,好让它最终转换为屏幕上的像素点来进行呈现(此时基本就是带有rgba颜色的点了)。
至此,我们简单了解了图形学中的三个要素:顶点、图元与片元。本来,接下来的内容应该介绍渲染管线了。但是笔者思考以后始终觉得,直接搬出一些概念,还是不够直观,初学者很容易被劝退。所以在介绍渲染管线之前,笔者决定先介绍一下在图形学中的空间变换。
图形学中的空间变换
模型空间与世界空间
假设我们制作了一个边长为2的立方体,如下图所示:
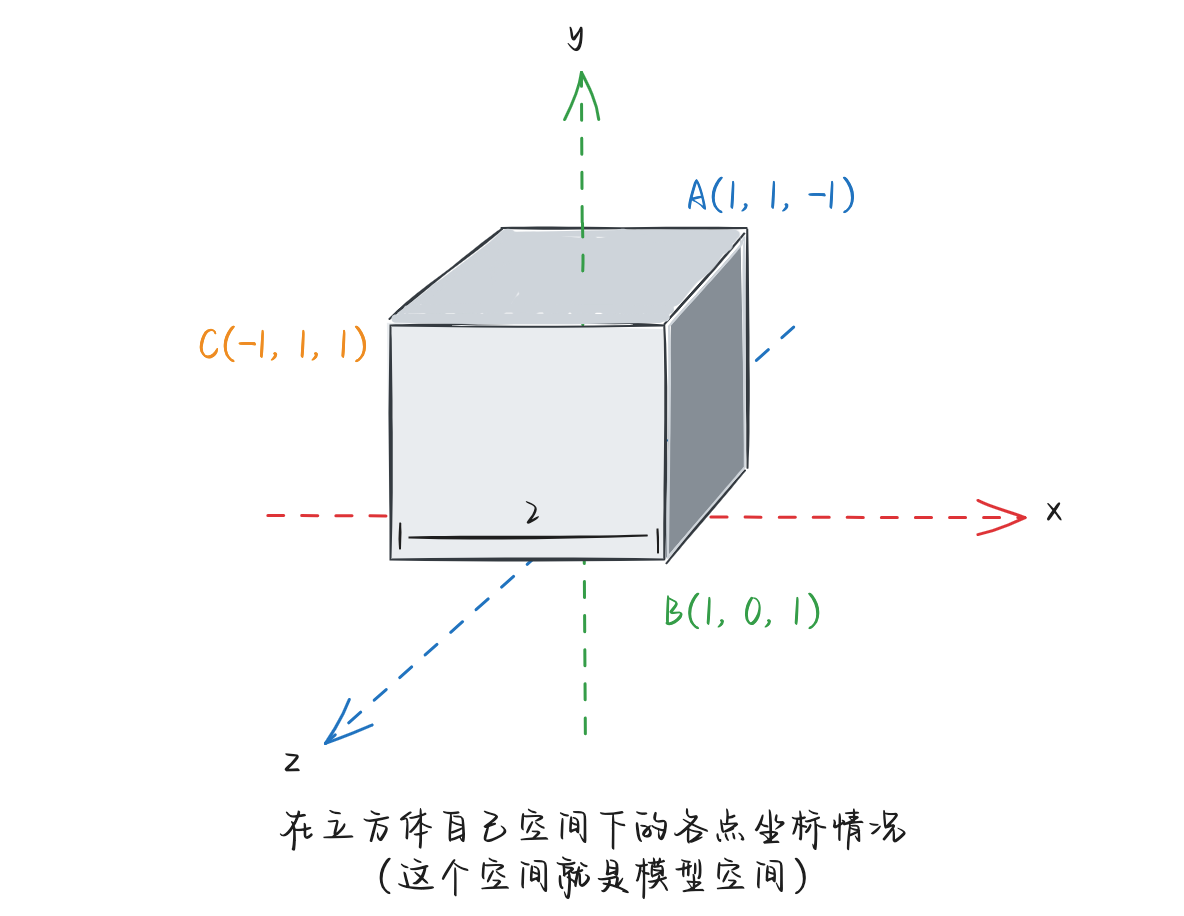
此时,这个立方体我们是在当前坐标系中创建出来的。所以它的各个点的位置就如上图所示(例如图中标识的三个点:(1, 0, 1)、(1, 1, -1)以及(-1, 1, 1)等)。
随后,我们将这个立方体放置到一个“世界”场景中,在此之前,“世界”场景中已经有了一个球体:
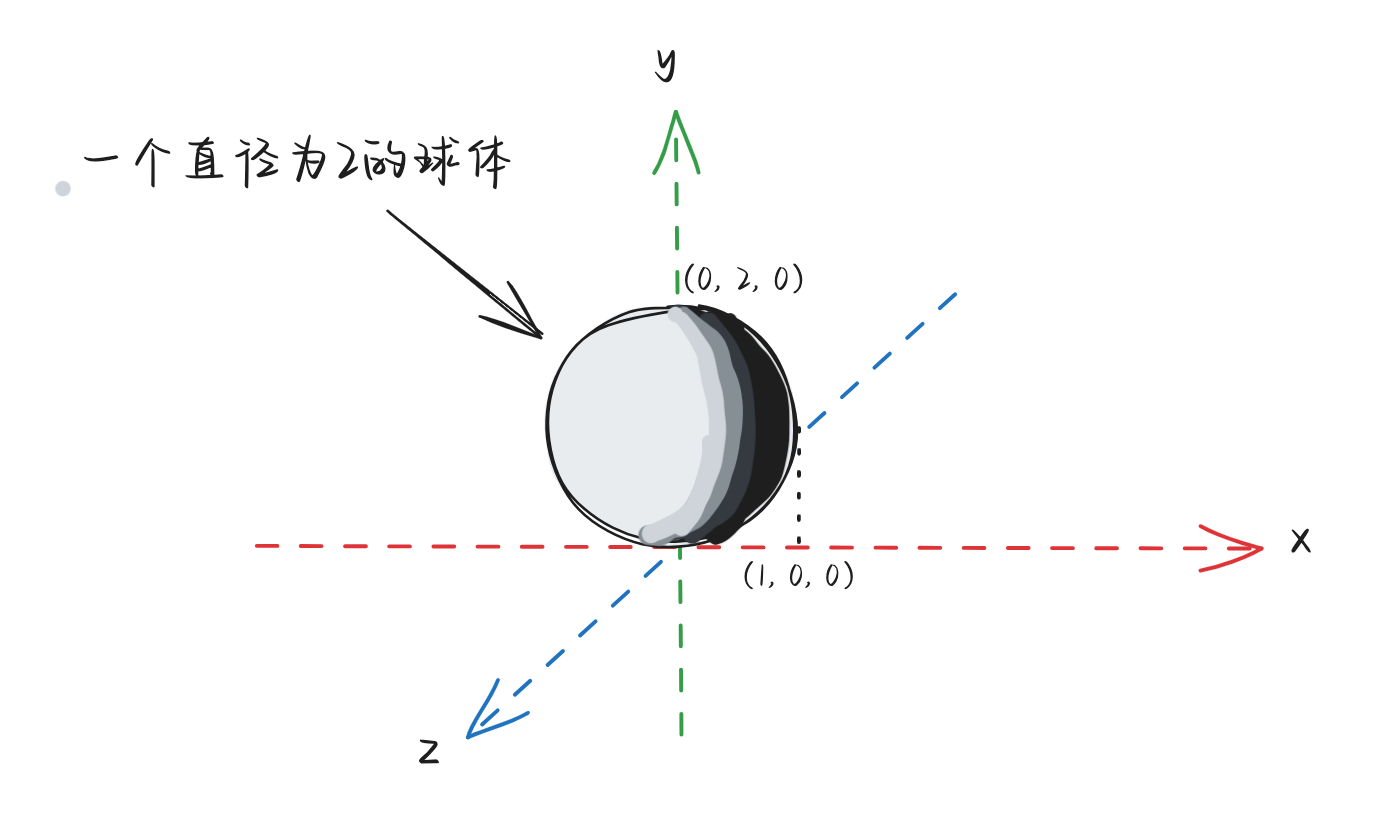
为了不让他们重叠,我们将这个立方体先将边长从原来的2缩小到1个单位,然后放置到如下位置:
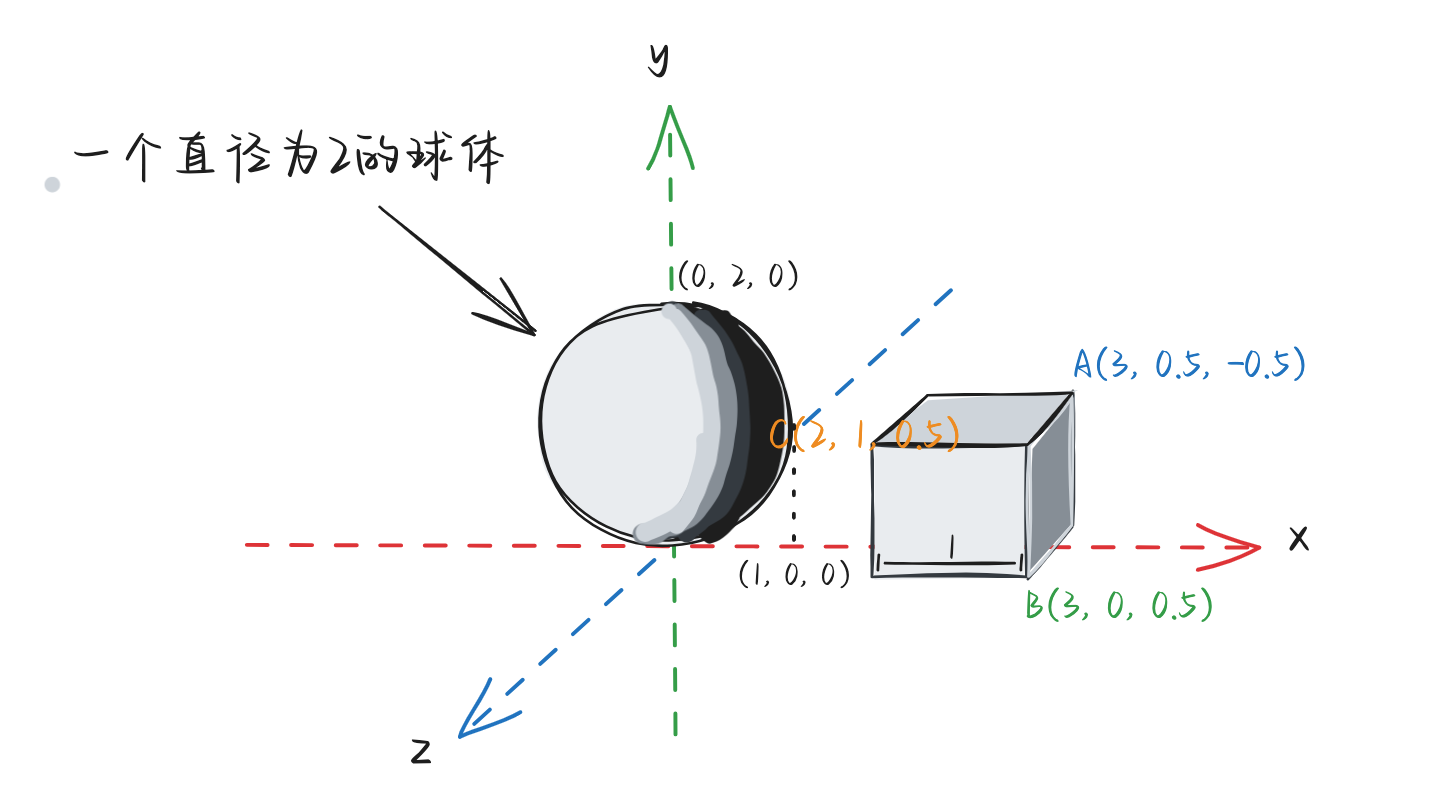
注意看,此时我们的立方体的坐标在此刻与球体共存的世界中的ABC三个点的坐标就不再是原有的坐标,而是在这个“世界”下的坐标(A(3, 0.5, -0.5)、B(3, 0, 0.5)、C(2, 1, 0.5)),这个过程,其实就是将“模型空间”转换到“世界空间”(的坐标)的过程。
“模型空间”的意义是每个三维物体本身在自己的一个空间坐标系下(又叫“局部坐标空间”),我们去定义这个物体的三维数据的时候,不依赖于外部,而是一个纯粹的当前物体的一个空间。
然而,我们将一个物体创造好以后,我们一般都需要将它放置到一个和其他的物体在一起的一个地方,组成一个场景,使之更有意义,而这个地方就是“世界空间”,在这个过程中,我们一般会对某个单独的模型物体进行旋转、缩放等操作,以便让它更加协调的存在于这个“世界空间”中。
观察空间
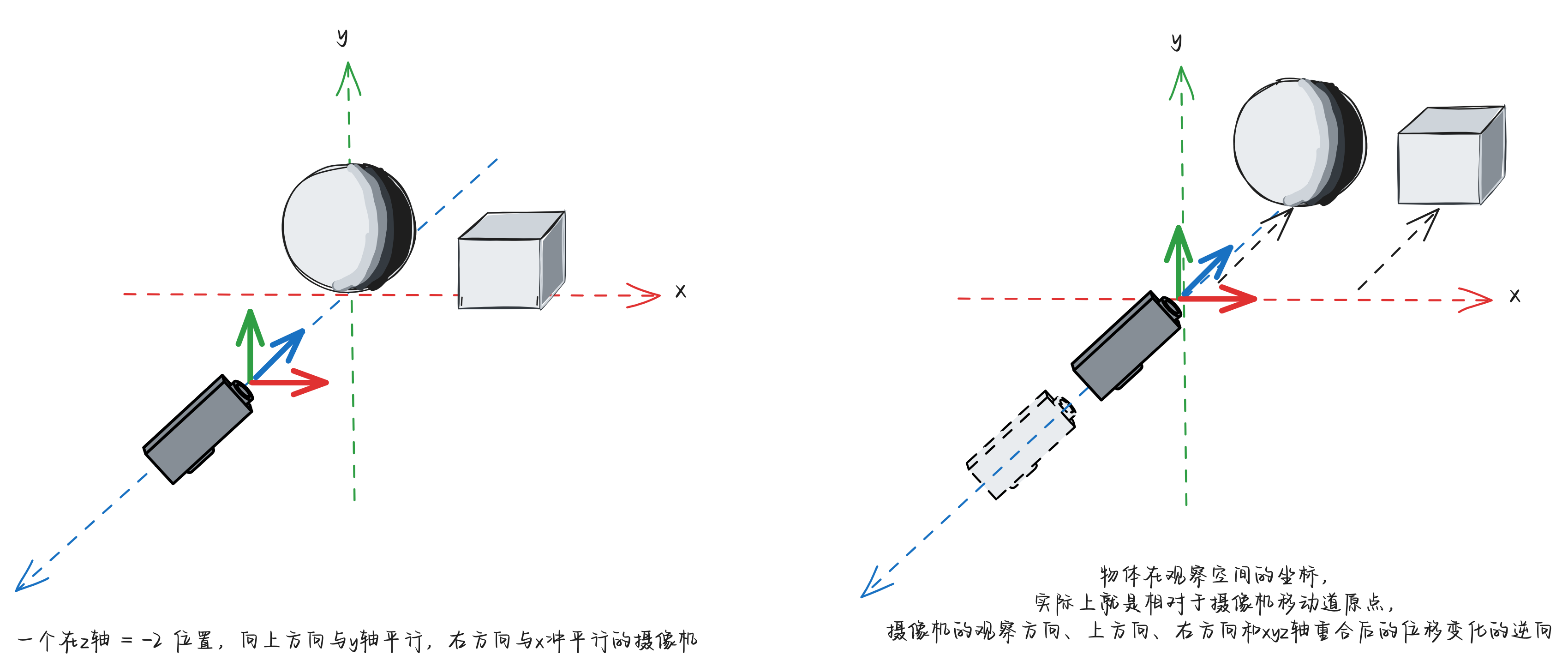
当得到世界空间下的坐标的时候,我们会进一步将其变换为“观察空间”。介绍“观察空间”前,我们需要先引入一个角色:摄像机。既然我们已经将“世界”准备好了(例如上面的一个立方体加上一个球体的场景),我们总是需要“观察”它,不然就没有意义了。因此,我们就会需要一个类似“摄像机”的角色。这个摄像机会包含有3个要素:1、摄像机的位置;2、摄像机看向的目标方向;3、摄像机的向上方法。对于摄像机的位置和看向的目标方向容易理解,对于摄像机的向上方向,用下面的示例应该也很好理解了:
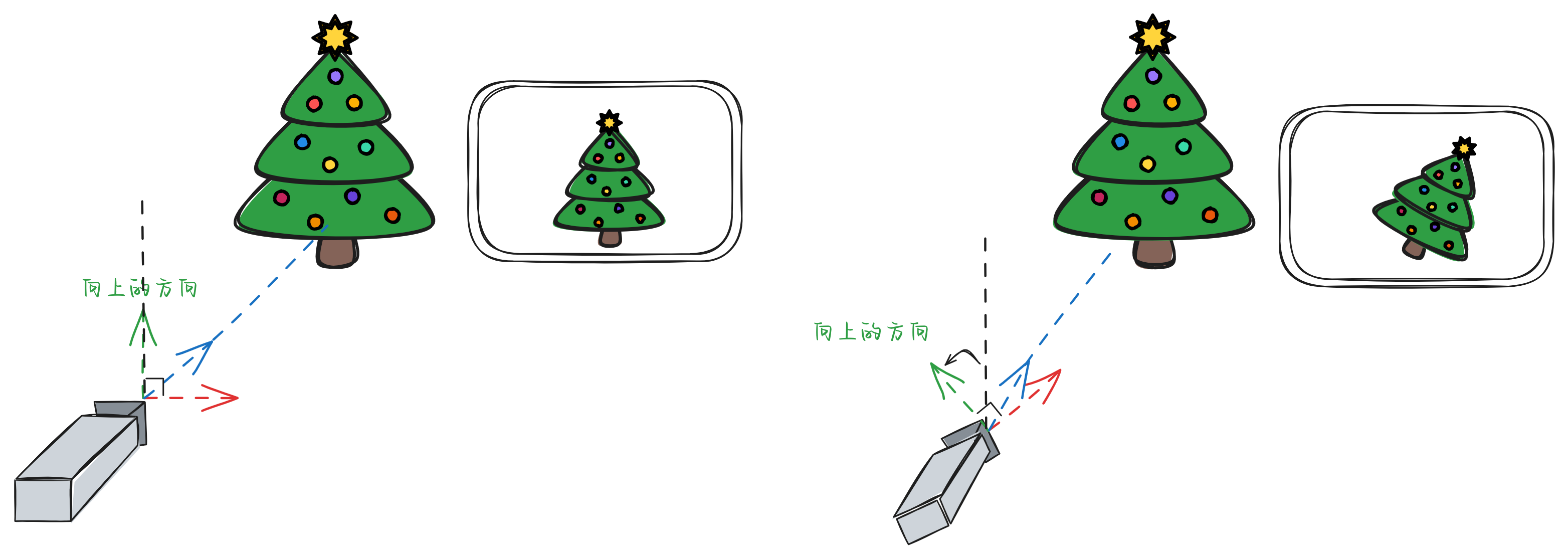
上图中,我们首先在空间的某处放置一个摄像机,让它“看向”一棵树,我们使用蓝色向量表示出这个方向;通过这个蓝色的向量的方向和摄像机所在的位置,我们可以确定唯一一个让蓝色向量垂直的平面。在这个平面上, 我们可以找到无限组相互垂直的向量(例如上图左右两个摄像机的的红、绿色向量,我们可以绕着蓝色向量方向转动,还能得到更多的红、绿向量),其中,我们会把红色的向量定义为摄像机的右向量,那么垂直于红、蓝向量平面的绿向量就是向上的向量。摄像机向上方向的不同,会导致图像摄像机拍摄的物体的向上方向不同。
注意,这里的红绿蓝向量,其实和一些教程(例如《[摄像机 - LearnOpenGL CN (learnopengl-cn.github.io)](https://learnopengl-cn.github.io/01 Getting started/09 Camera/)》)是不太一致的。本文只是从现实出发,使用一种容易理解的方式来介绍概念,并不是完全的考虑计算层面的事情。
有了确定的摄像机以后,我们需要进行这样的操作。将摄像机和整个世界做一次整体的位移操作,让摄像机移动到原点,观察方向与Z轴重合,上方向与Y轴重合,同时让“世界”中的物体保持与摄像机相对不变:
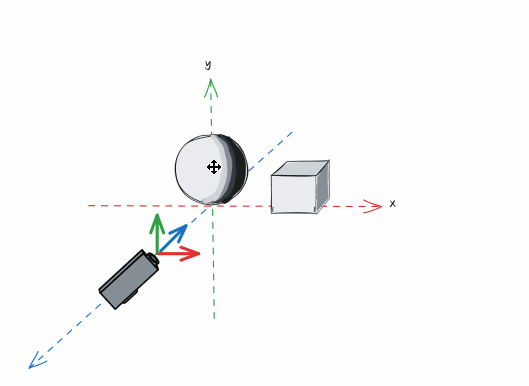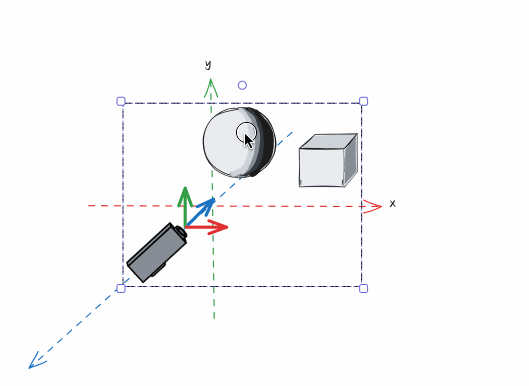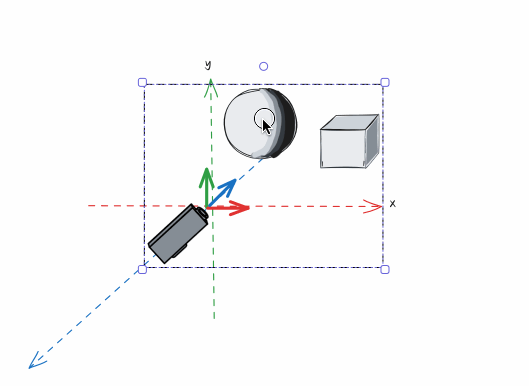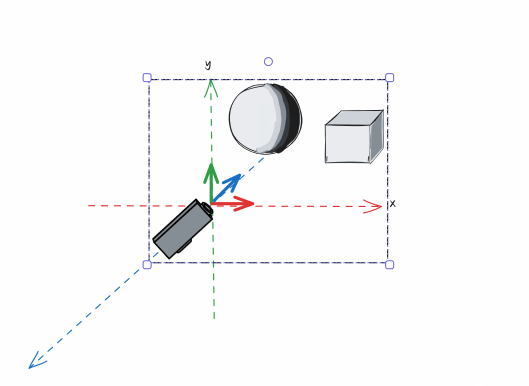
在完成移动以后,原先的物体的坐标在摄像机处于原点的坐标空间下有了新的坐标位置(例如,原本我们的球体最顶部的点坐标是(0, 2, 0),经过将世界空间转变为观察空间,就成了(0, 2, -2)),而这个过程就是“世界空间”转变为“观察空间”,摄像机处于原点的坐标空间就是“观察空间”。
为什么有观察空间?因为将摄像机放到原点的过程后,对于后续的观察投影处理很方便。
经过一系列的操作,我们已经将一个2x2x2的立方体,从模型空间变换到了观察空间:
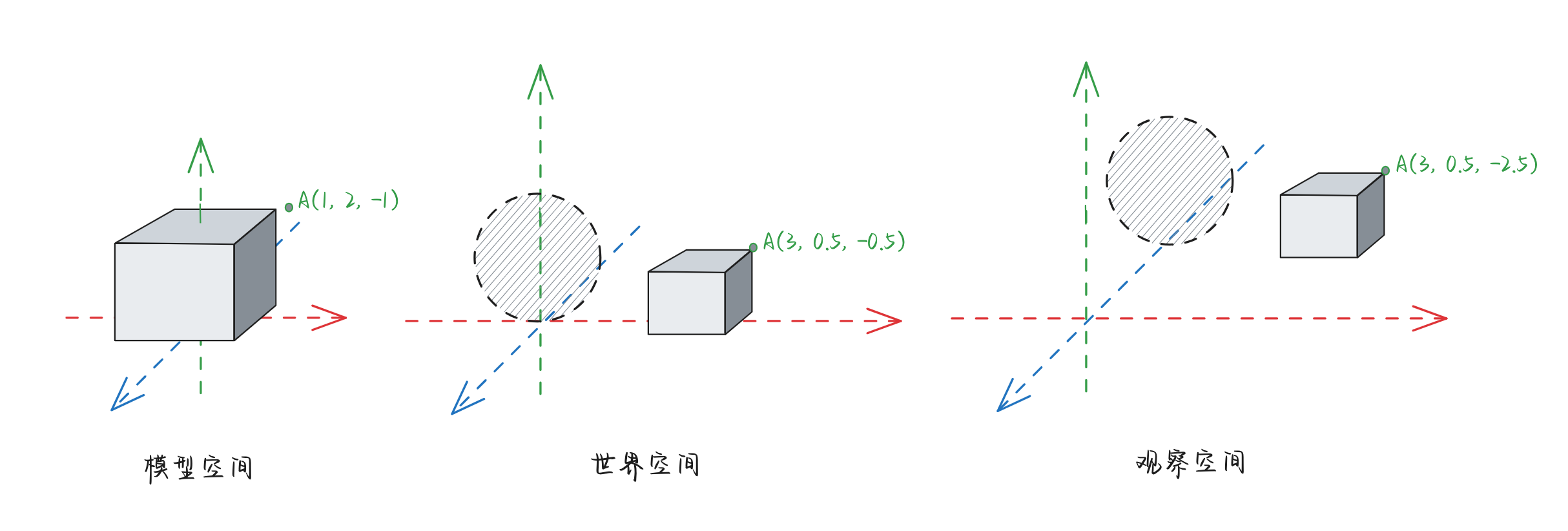
注意看上图立方体A点的左边经过一系列变换的结果
在观察空间的基础上(此时摄像机就在观察空间的原点),我们就会开始进行投影处理。正如一开始介绍的,投影一般来说分为两种:1)正射投影;2)透视投影。
对于上面我们创建的球体和立方体,摄像机放在原点,分别使用正摄像投影和透视投影的效果大致如下:
容易理解的是,经过投影以后,我们将三维立体的物体转变为了二维图像。原先三维空间中任意一个点,都“投射”到了二维空间上。如果我们将这个二维空间视为我们的显示器屏幕。那么很显然,我们需要将“观察空间”中某一个三维坐标点通过一定的方式的计算变换,得到在屏幕上某个具体位置的像素。
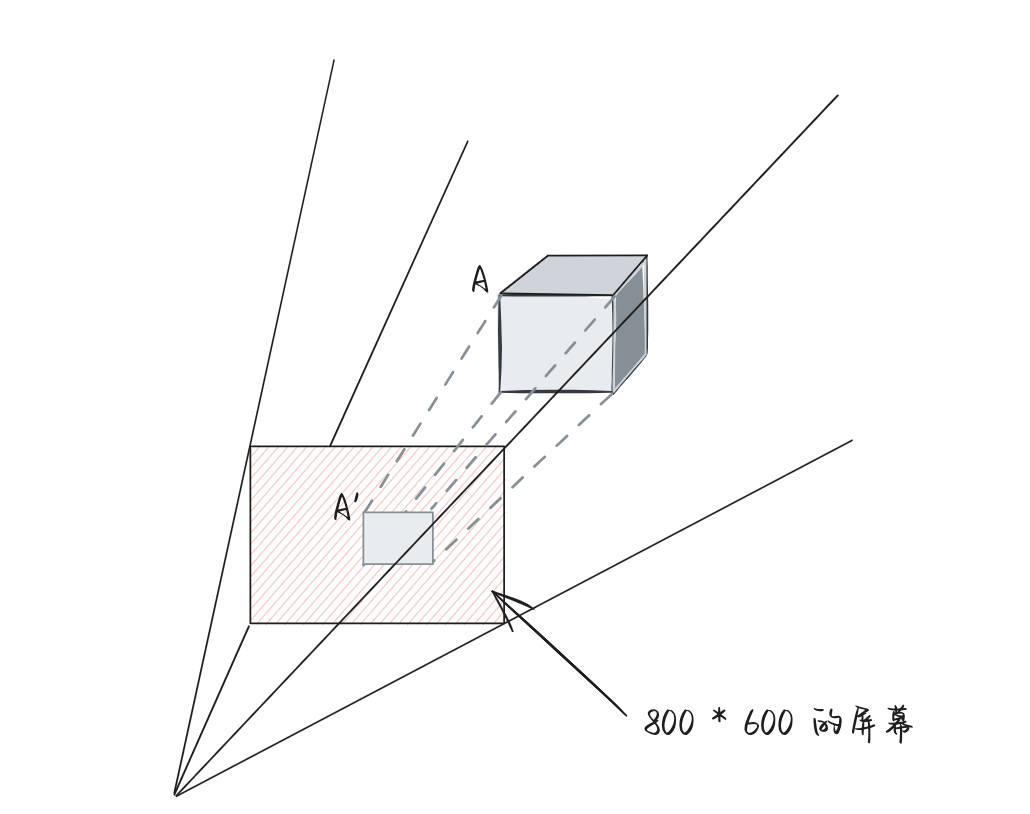
对于上图,原本在观察空间中的点A的坐标,会通过一定的上下文(摄像机的距离、FOV视野等)通过一定的数据计算,来得到A',而这个A'是屏幕上的某个x、y均为整数的像素坐标。
写在最后
本文就大致介绍关于图形学中的一些基本要素,以及空间变换。在后面的文章中,会逐步介绍计算机图形学中的一些内容,例如渲染管线等。