在上一篇文章中,我们介绍了Wgpu中的渲染管线与着色器的概念以及基本用法。相信读者还记得,我们在渲染一个三角形的时候,使用了三角形的三个顶点的索引作为了顶点着色器的输入,并根据索引值计算了三个几何顶点在视口中的位置,并通过片元着色器的代码逻辑,控制了每一个像素都用红色色值,最终渲染了一个红色三角形:

当然,我们不可能一直使用wgpu来渲染这样的简单固定的图形。面对实际的场景,我们有时候需要根据一些上下文来动态的修改渲染图形的大小形状。在本文中,我们将开始介绍顶点缓冲区的概念,来为后续实际的场景做一些铺垫。
认识缓冲区
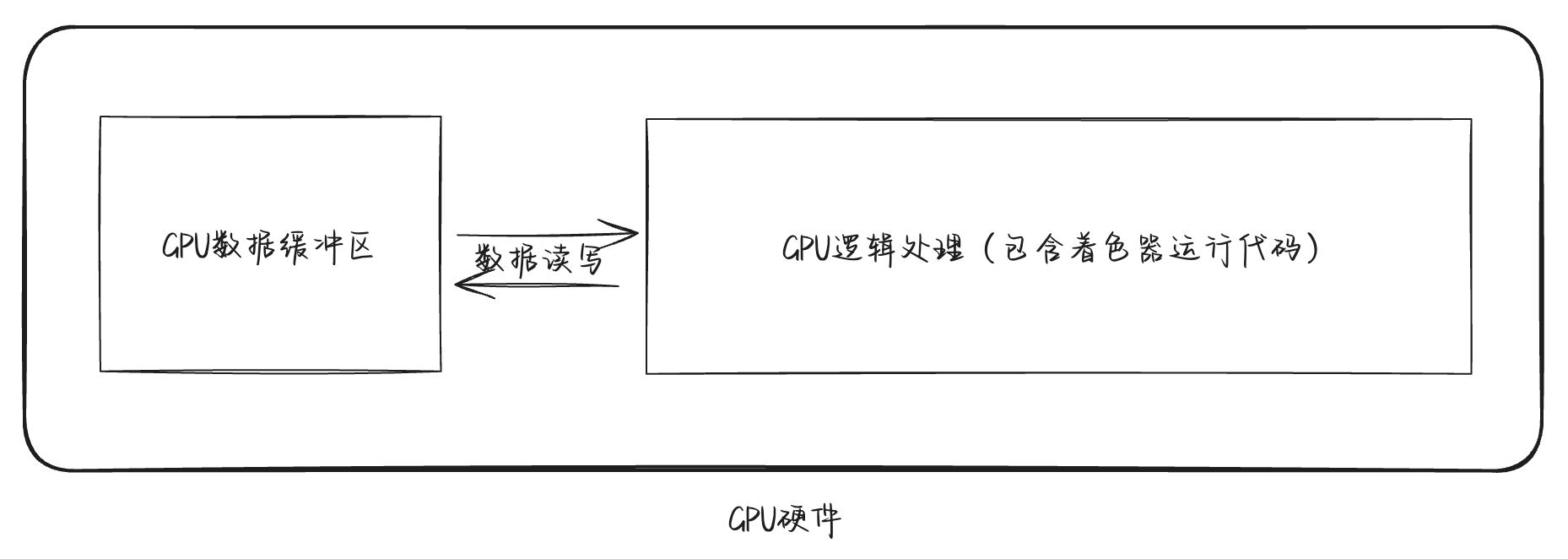
缓冲区(Buffer)一个可用于 GPU 操作的内存块(又叫“显存”)。在wgpu(或其他例如OpenGL等库)中的缓冲区概念通常指的是 GPU 能读写的内存区域,与之对应的就是我们常见的CPU内存。回想一下常规的软件运行的过程:程序在启动后,会在“内存”中申请一块能够存放数据的区域。在运行的过程中,我们的代码指令按照既定的逻辑做着计算,并不断的读、写内存区域里面的数据,以达到期望的程序运行的结果。不严谨地讲,GPU 与 CPU 是一样的,它同样能够执行计算逻辑,同样会有数据存储的区域,这个区域就是 GPU 的缓冲区。
一般来说,我们都在 CPU 直接阶段,在内存中将一些初始的数据准备好,通过一定的方式发送给 GPU,并存储在GPU上的缓冲区中。在执行的过程中,我们可以通过着色器代码来读取缓冲区中的数据:
创建顶点缓冲区
为了更好的管理不同类型的数据(比如常见的有顶点数据、顶点索引数据),我们会按照其不同类型来设定不同的缓冲区。在本文中,我们先介绍如何创建并使用顶点缓冲区,对于其他缓冲区我们会在后续的文章中说明。
顶点缓冲区,顾名思义,就是包含了在渲染过程中会使用到的顶点数据的 GPU 显存区域。需要注意的是,图形学中的顶点并不是我们常规意义上的几何顶点,而是包含了位置坐标、颜色信息、纹理坐标以及法线向量等的顶点数据,常规意义上的几何顶点仅仅是顶点数据中的一部分。
在上一篇文章中,尽管在最后我们成功终绘制了一个三角形,但实际上它的三个顶点位置是通过三个顶点索引(0、1、2)计算而来的。假设我期望绘制一个比较另类的三角形或其他图形,纯粹靠顶点索引是不够的。这种场景我们一般会按照如下的方式进行:
- 准备一些包含自定义位置信息的顶点数据;
- 将顶点数据放置到顶点缓冲区中,并进行一定的配置;
- 最后,在着色器代码中通过一定的方式读取这些顶点数据,并交给顶点着色器来使用。
接下来让我们开始实践如何通过编程方式创建顶点缓冲区。
假设最终我们期望渲染一个由(0, 1)、(-0.5, -0.5)、(0.5, 0)三个2维顶点构成的三角形:
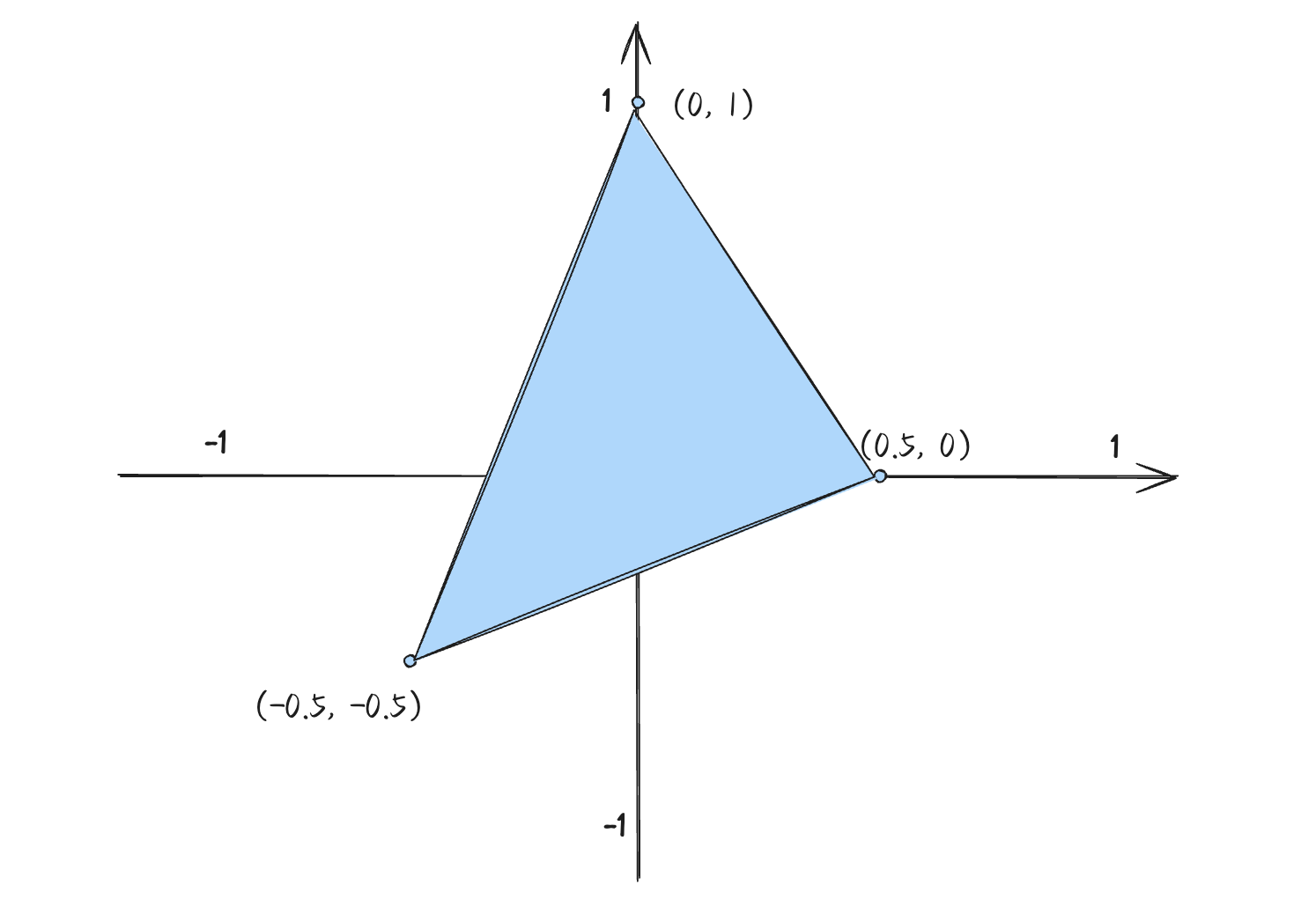
首先,让我们在基础项目中增加一个结构体Vertex,用来表达我们的顶点:
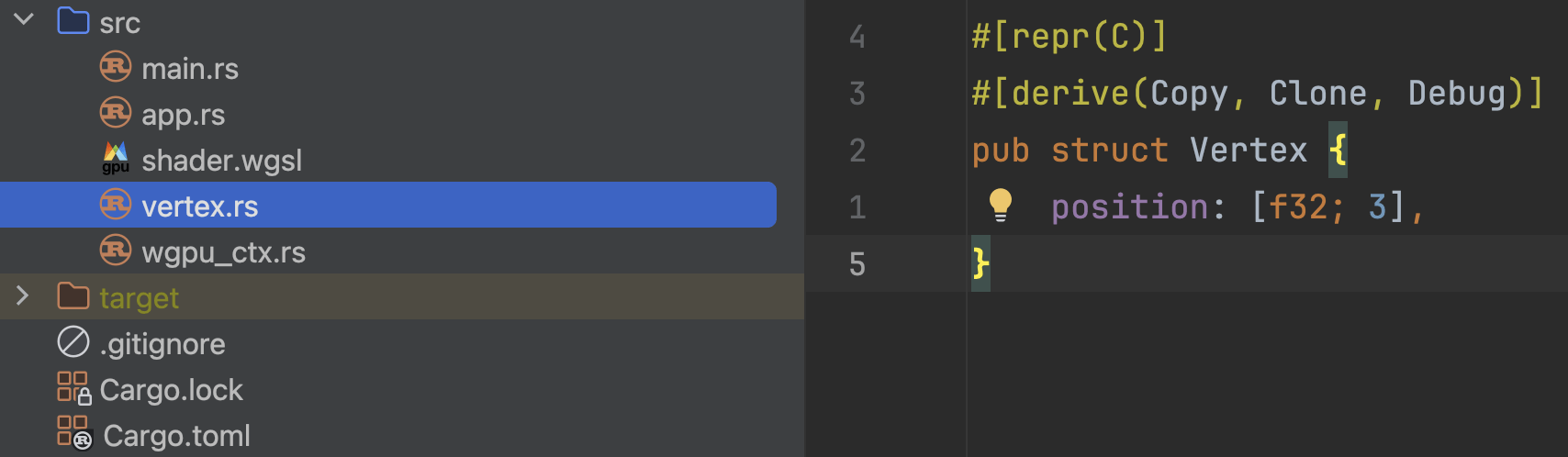
这个结构体我们现在仅有一个类型为[f32; 3]类型的字段position,用来表示一个位置坐标。
⚠️这里务必添加Copy派生
引申:关于内存布局
该结构体上的属性,除了我们常见用来派生Copy、Clone等trait的derive属性外,还有一个特殊的属性:#[repr(C)],在配置该属性后,Rust 编译器会强制按照 C 编译器的编译方式来安排结构体字段的顺序和对齐方式。假设有如下结构体,在#[repr(C)]的加持下,其内存布局会保持4字节对齐:

上面的结构体中,age字段的类型是u8,但因为强制使用了#[repr(C)],让其保持了4字节的内存布局。我们可以用如下的代码来验证:
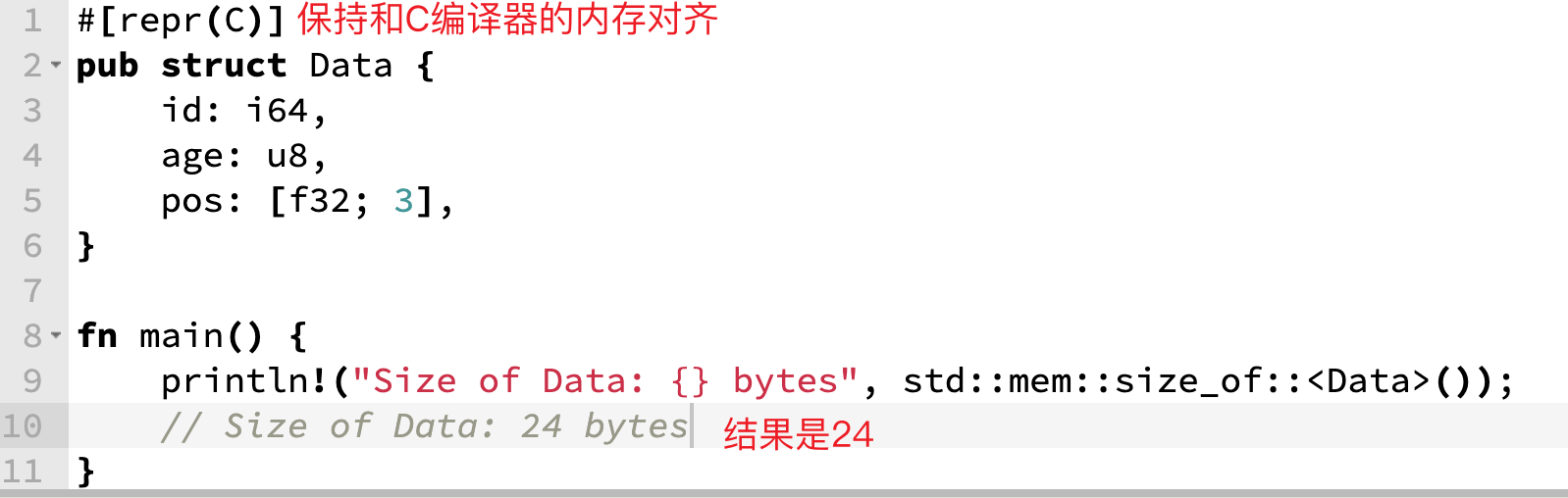
当然,有的小伙伴会发现即使不添加#[repr(C)],结果也是24bytes,是因为Rust编译器在某些场景下会进行对齐,不过这样无法保证是按照和C编译器一样的4字节对齐;此外,Rust编译器在有时为了内存的高效利用,可能会进行布局压缩。当然,你还可以使用#[repr(packed)]来禁用内存对齐填充:

好了,让我们回归正文。此时我们已经编写了一个Vertex结构体,也理解了#[repr(C)]的意义。接下来,我们创建一个数组切片来存放三个顶点的数据:
1 | |
在编写了三个顶点的数据后,我们更进一步,将顶点缓冲区创建出来消费顶点数据。
首先,让我们在async_new方法中的合适位置通过调用Device实例的create_buffer_init方法创建一个顶点缓冲区对象:
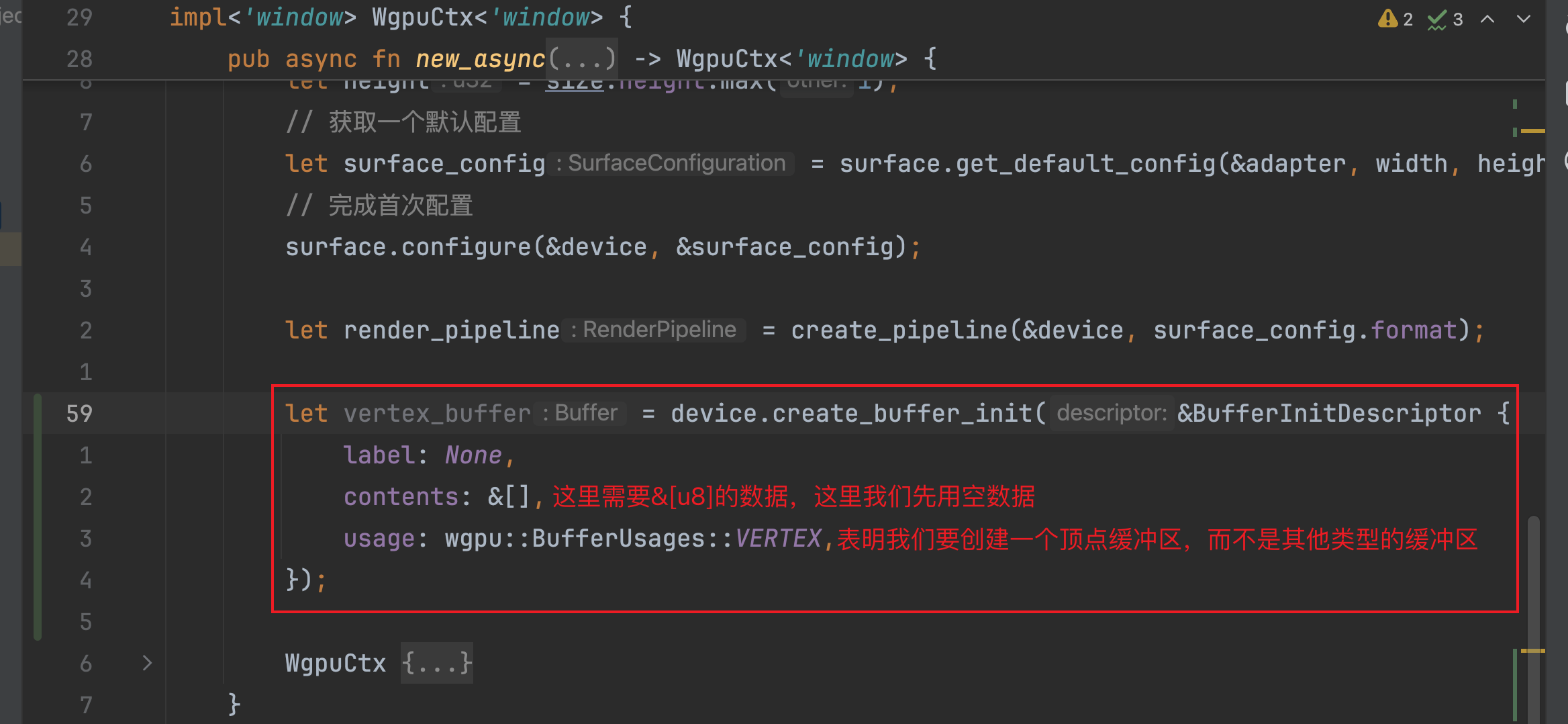
contents字段需要我们提供&[u8]类型的数据,即字节数组的切片引用,这里我们先传空,待会儿会讲到如何将我们的VERTEX_LIST数据转为&[u8]类型的数据;usage字段我们现在传入 wgpu::BufferUsages::VERTEX这个枚举,表明我们要创建的是一个顶点缓冲区,而不是其他的缓冲区。
接下来,我们尝试将前面创建的VERTEX_LIST数据转换为&[u8]字节数据。这里我们使用一个工具库bytemuck,该库可以方便的将我们的一些数据结构转为内存中的字节数据。其具体方式如下:
- 在依赖中添加
bytemuck - 修改
Vertex结构体的内容:
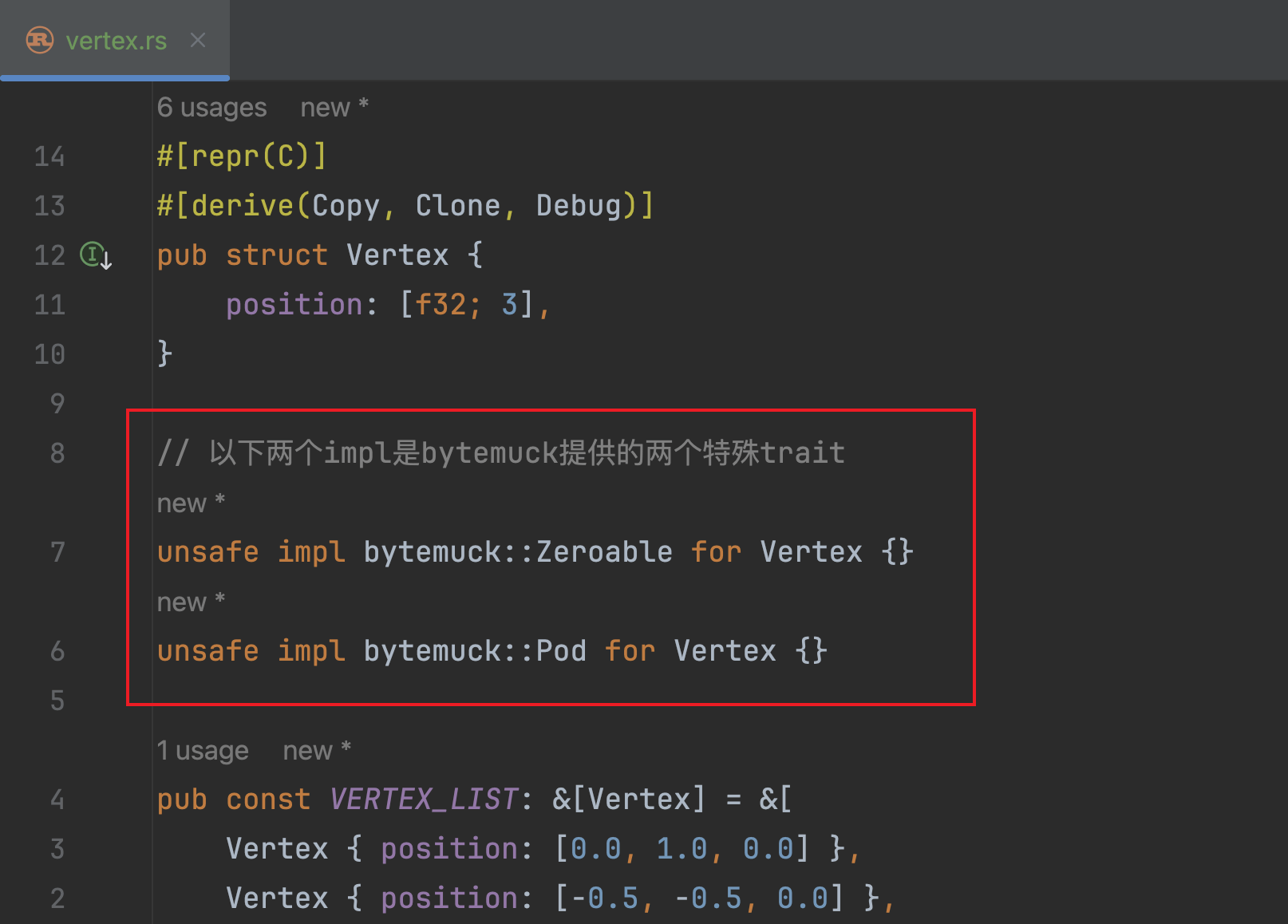
- 在创建缓冲区的地方添加如下的转换代码:
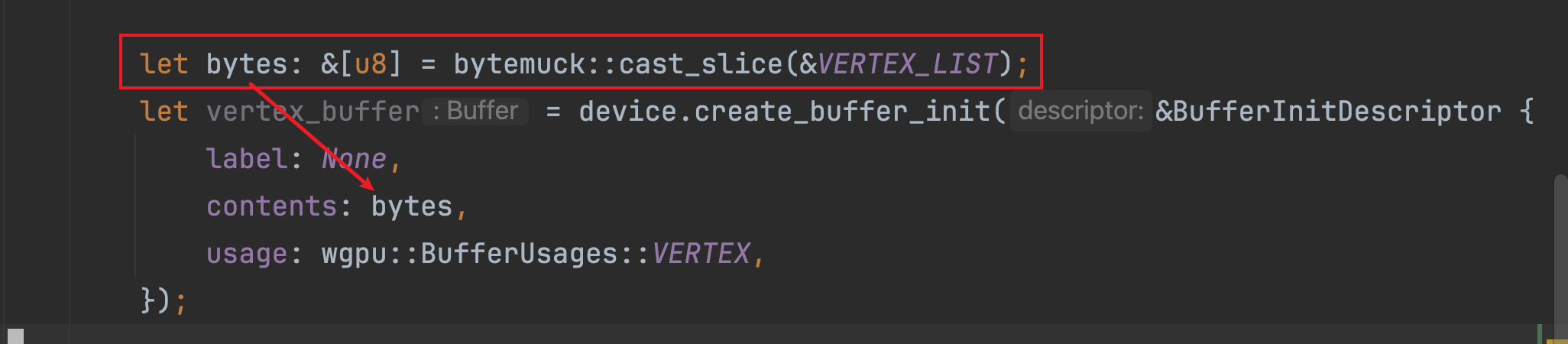
调用bytemuck的cast_slice方法,将原始数据转为u8的切片,并作为contents字段的值传入
- 修改
WgpuCtx结构体,保存我们本次创建的顶点缓冲区实例:

总结一下,为了创建一个顶点缓冲区,我们经历如下几步:
- 定义一个结构体(
Vertex)来表示一个顶点数据,该结构体除开配置#[derive(Copy, Clone)]属性外,还需要使用#[repr(C)]来保证该结构体在编译后的内存布局及对齐字节数据保持和C编译器一样;以及,让结构体实现来自bytemuck库提供的Pod和Zeroable两个trait,以供后续通过bytemuck的提供的API来将数据转为&[u8]。 - 完成
Vertex结构体的定义后,我们又根据最终想要渲染的三角形的几何结构,使用VERTEX_LIST来存储了三个顶点数据。 - 使用
bytemuck提供的API将VERTEX_LIST通过将其转为了u8字节数组切片字节数据。 - 调用Device提供的API
create_buffer_init,传入顶点数组字节数据,以创建一个顶点缓冲区实例。 - 将顶点缓冲区实例存储到WgpuCtx实例,以供后续消费使用。
至此,对于创建顶点缓冲区部分的介绍就到此为止。接下来我们需要介绍另一个同样重要的内容:顶点缓冲区布局(VertexBufferLayout)。
创建顶点缓冲区布局
首先,我们需要明白为什么会有缓冲区布局这一东西。假设现在在 GPU 显存中有如下的一段数据:

在没有其他上下文的情况下,我们无法理解这段内存中的数据有何意义。同样的,如果我们单是把先前创建的顶点数据放入顶点缓冲区中,在实际渲染的过程中,GPU 也无法理解这一堆的二进制数据应该如何使用。此时,我们就需要用一些配置上下文来解释顶点缓冲区中的数据的具体意义。
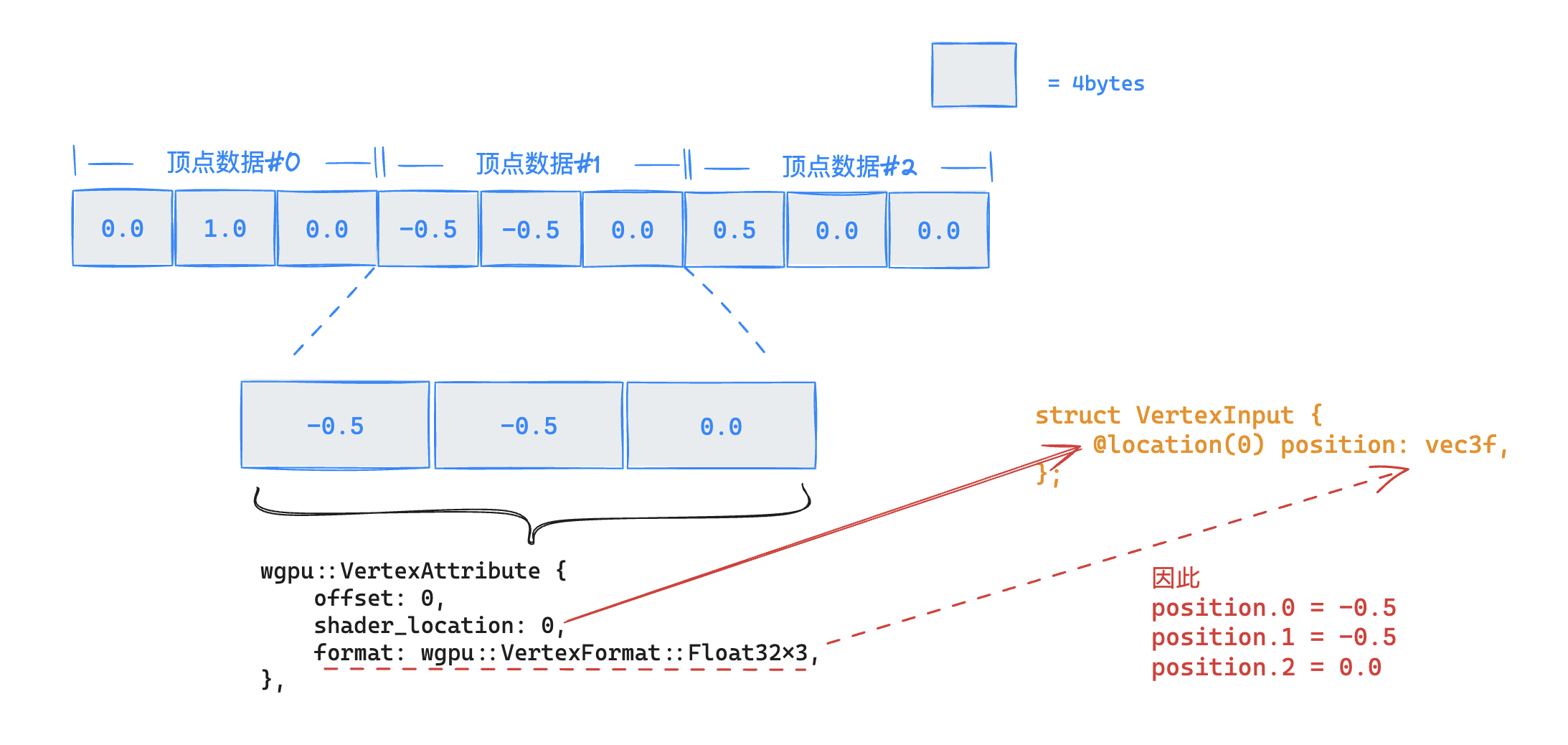
还是以上图数据为例,如果现在告诉你这是一段包含了3个顶点数据的内存布局,其步进(stride)是3字节(即每三个字节就算做一个顶点数据);同时,单看每一份顶点数据,按照从其偏移字节为0的地方开始是一份位置数据,其类型为3个float32(32bits,即4bytes)数据,现在对于这段内存中的数据的布局结构是不是变的比较清晰了呢:
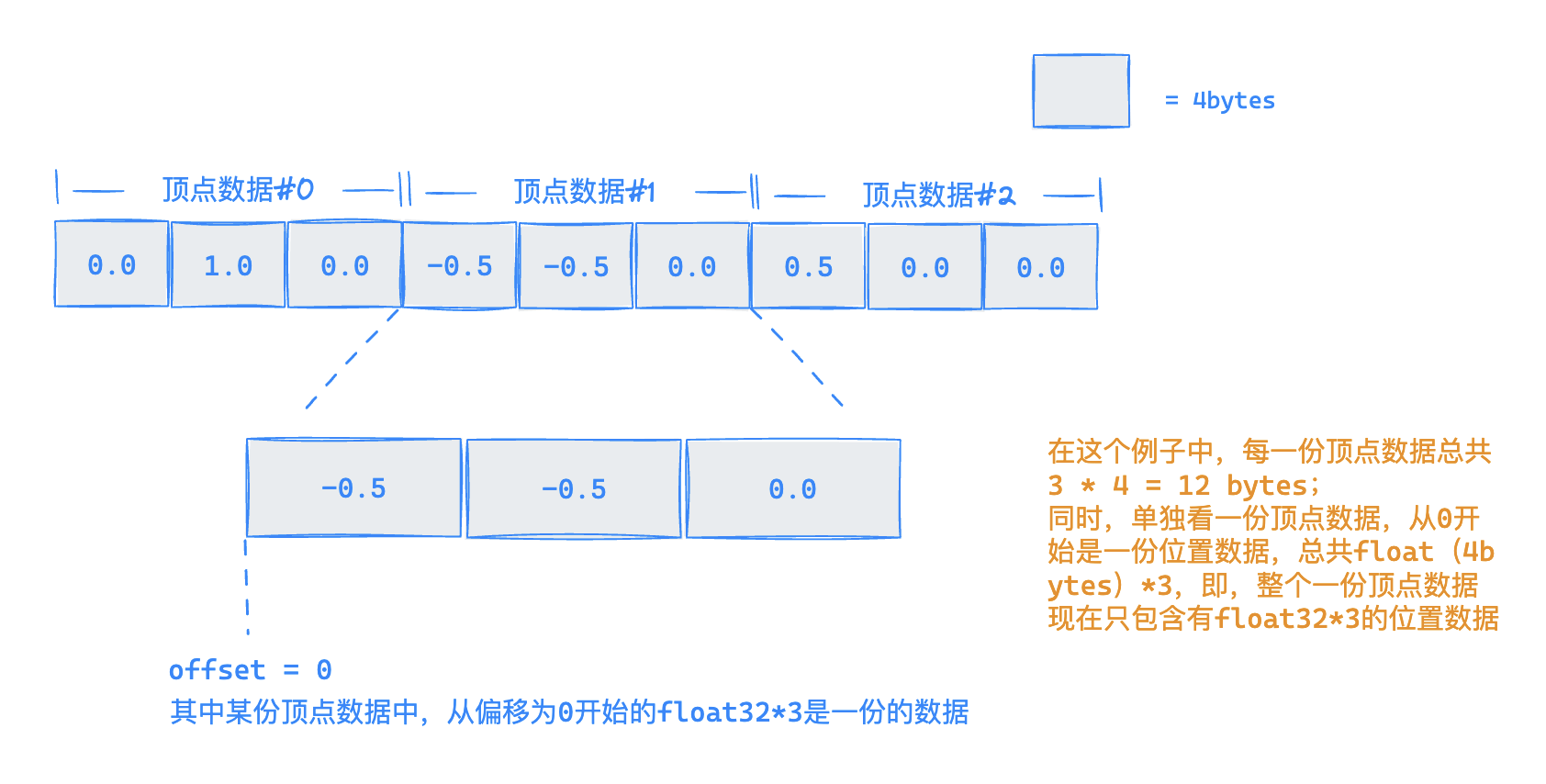
有了上述的说明,再回过头来就不难理解缓冲区布局的意义了。接下来就让我们通过代码实践来定义一个顶点缓冲区布局实例。
首先,我们依然在vertex.rs文件中增加一个方法,用来返回一个顶点缓冲区布局实例:
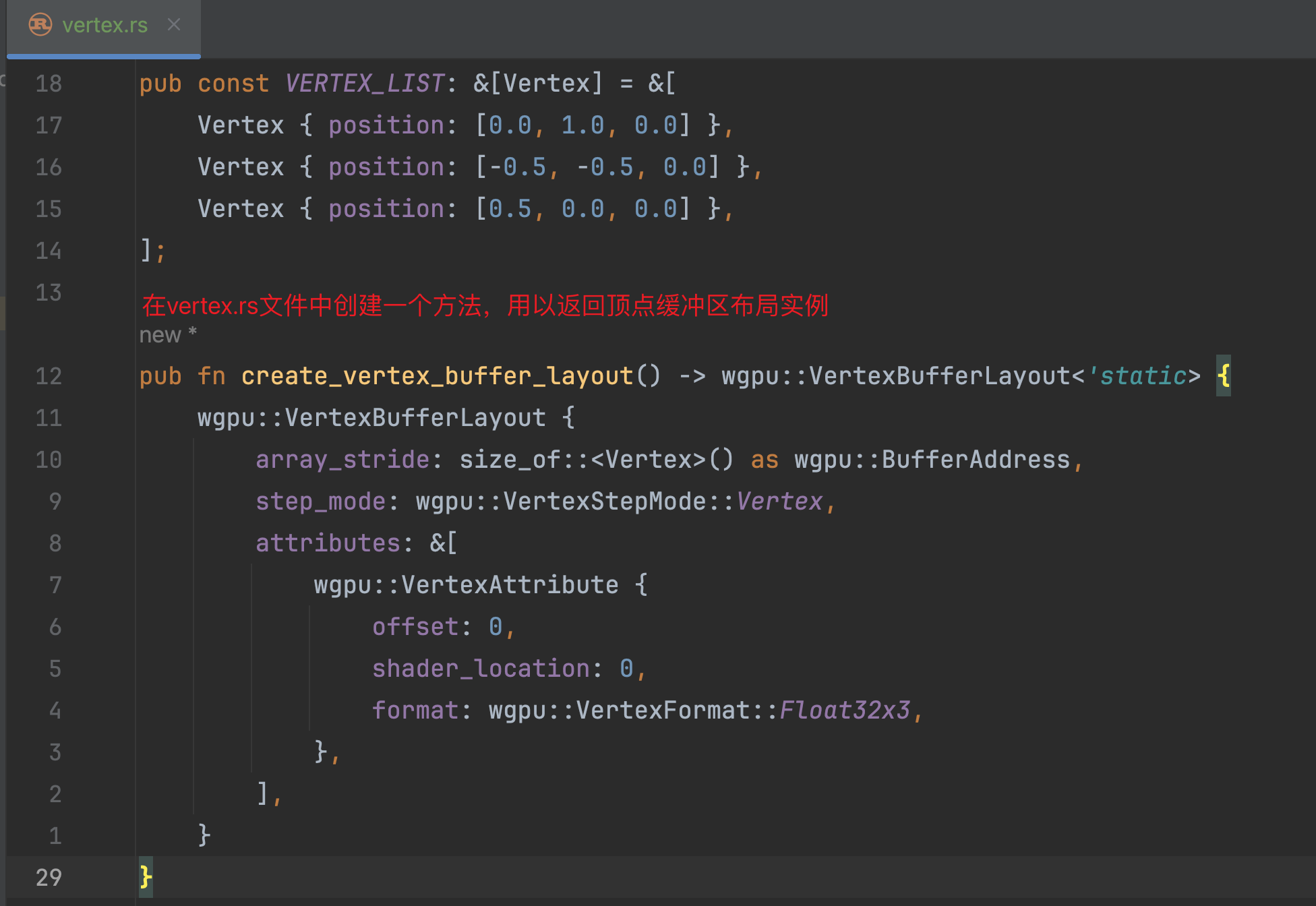
对于该方法的实现,我们就是返回了如下的一个结构体:
1 | |
-
字段
array_stride表示的就是每一份顶点数据在内存中的步进长度,在本例中,一个Vertex结构体在#[repr(C)]的属性配置下能够确保是12bytes。 -
字段
step_mode我们暂时不详细介绍,读者可以简单理解为告诉渲染管线每一份数据代表的是一个顶点数据(),这里默认使用该枚举值VertexStepMode::Vertex即可。 -
字段
attributes是一个数组切片引用,在这里我们只传递了一个VertexAttribute数据,表示就目前而言,我们一份顶点数据中,只有一份有意义的“子数据”。对于这份“子数据”,我们配置了offset、shader_location以及format字段。这三个字段整体表达了这样一个事实:在一份顶点数据中,从offset = 0开始有一段格式为Float32x3(float32 = 32bits = 4bytes, 乘以3就等于12bytes)的数据,这段数据在shader着色器上的location为0的位置。相信读者对offset和format应该能够理解,但是对于“这段数据在shader着色器上的location为0的位置”这句话还有些难以理解,别着急,我们后面会讲到的。
消费缓冲区及布局
总结下现状,我们首先创建了顶点缓冲区并将其作为vertex_buffer存放到了WgpuCtx实例中;同时,我们还编写一个名为create_vertex_buffer_layout的方法用来构造一个顶点缓冲区布局实例,接下来我们会使用到上面准备工作的成果了。
首先,让我们在WgpuCtx的draw方法中适当修改代码来消费顶点缓冲区:
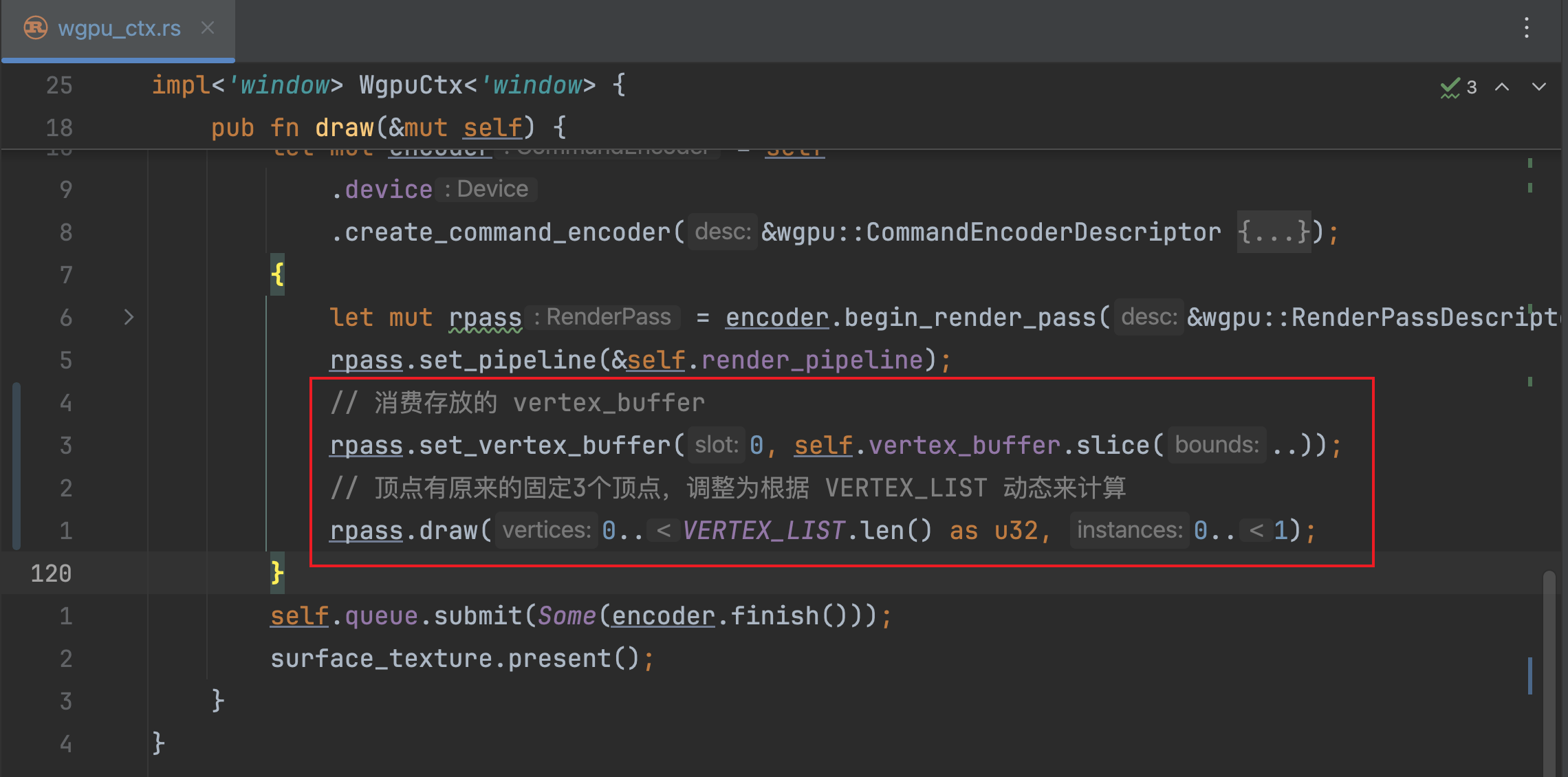
在调用渲染通道(RenderPass)实例的draw方法前,我们先调用set_vertex_buffer方法。该方法接受两个参数,第一个参数slot指的是我们要把顶点缓冲区中的数据放置到显存内部的顶点缓冲区域的哪个索引位置,这里我们设置为0,表示我们会设置到默认0的位置;第二个参数使用的缓冲区的数据片段,这里我们直接消费整个顶点数据,因此代码编写为slice(..)。
然后,修改draw的参数传递。将原来固定的0..3(即3个顶点)修改为动态的,根据我们创建的VERTEX_LIST的实际长度,这样在将来我们会创建更多的顶点的时候,就能够正确对应顶点数量。
完成消费顶点缓冲区的代码编写以后,接下来我们就需要再适当的位置创建缓冲区布局实例并消费它,其具体做法是:
调用create_vertex_buffer_layout方法得到缓冲区布局实例对象;把该实例对象传递给如下VertexState的buffers字段:
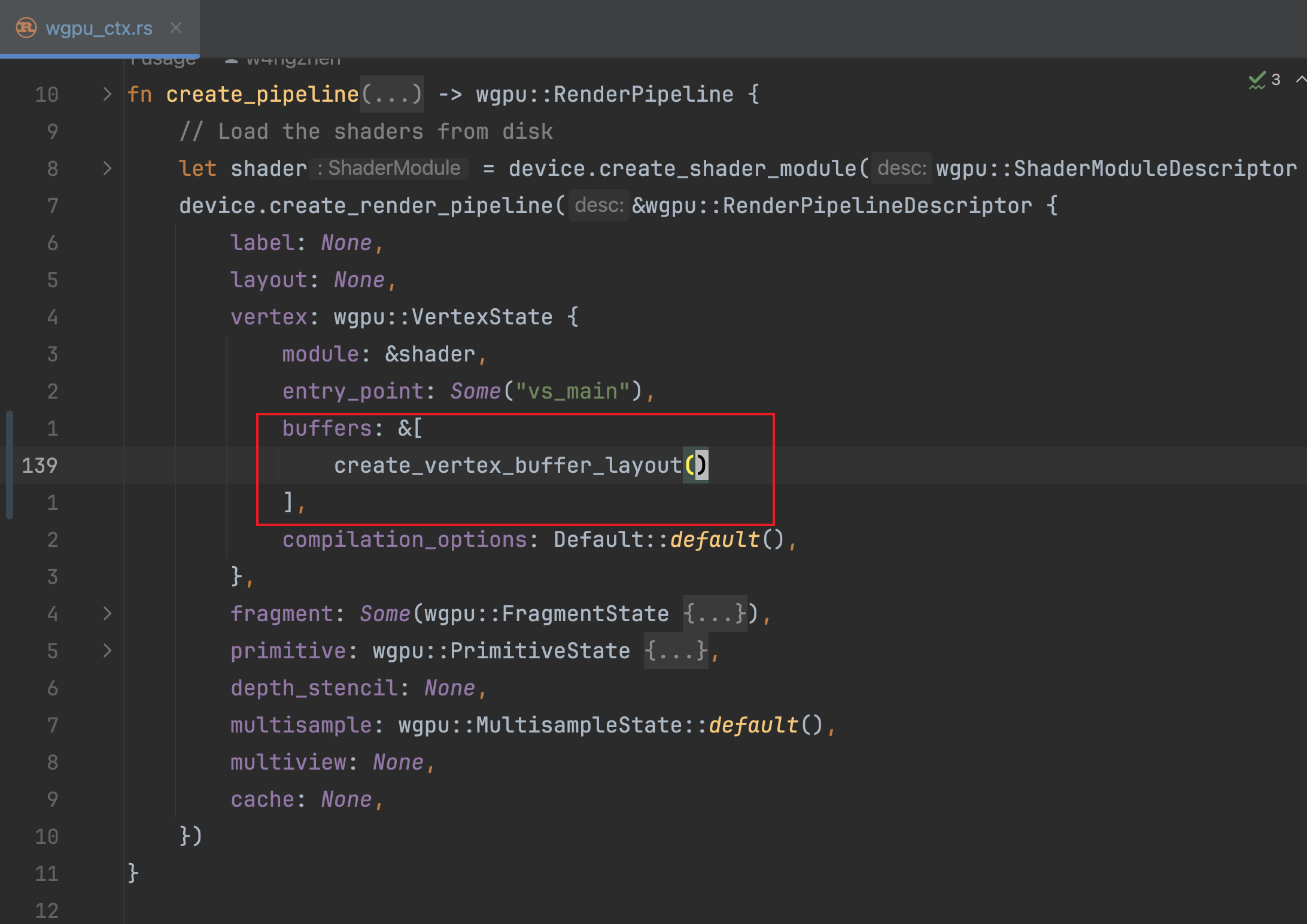
这个地方叫做buffers,但是实际上是要传buffer布局,maybe命名有点让人误导。
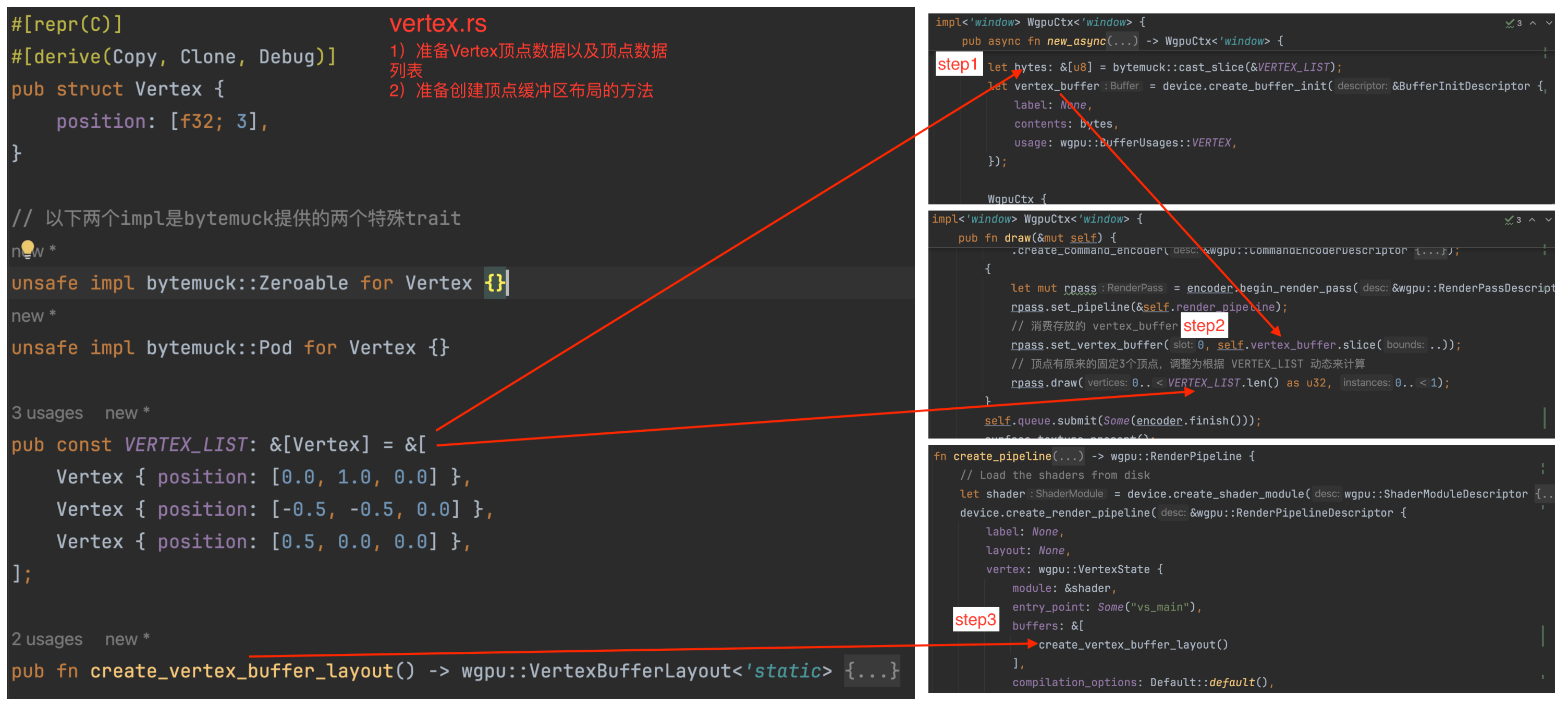
到目前为止内容偏多,让我们通过下图做一个简单的总结:
修改顶点着色器程序
上面的实践过程,我们仅仅是创建并消费了顶点缓冲区以及顶点缓冲区布局实例。然而,如果在此时运行程序代码,读者会发现窗口中依然是先前的一个撑满窗口的红色三角形。很显然,我们需要适当的修改着色器程序的代码,才能真正消费到我们在上面产生的有关顶点数据。让我们对shader.wgsl做出如下的修改:

首先,我们在着色器代码中定义了一个结构体VertexInput,这个结构体包含有一个position字段,其类型为vec3f。
值得注意的是,这个字段有一个前置的注解@location(0)。还记得前面我们说过:“这段数据在shader着色器上的location为0的位置”这句话吗?其实这里的location(0)对应匹配的就是前面在定义顶点缓冲区布局的shader_location配置:
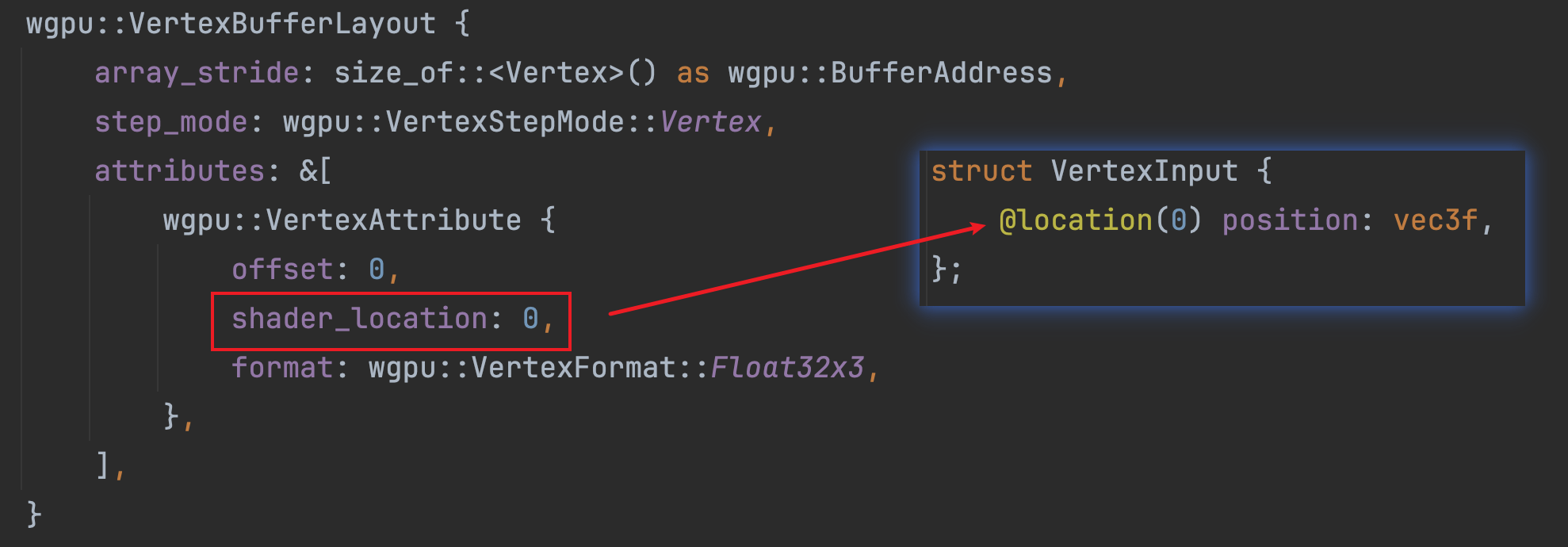
对于顶点数据、顶点缓冲区布局配置以及着色器中VertexInput的结构定义,我们就可以用下图来解释它们的关系了:
再看顶点着色器vs_main的部分,其入参由原来的@builtin(vertex_index) in_vertex_index: u32修改为了vertex_in: VertexInput。在每次顶点着色器运行的时候,渲染管线会结合顶点缓冲区布局配置以及每一份内存中的顶点数据,为我们构建一个VertexInput结构体实例,并传入该顶点着色器方法中。在这里我们就可以直接读取到对应的position位置字段数据并直接返回了。
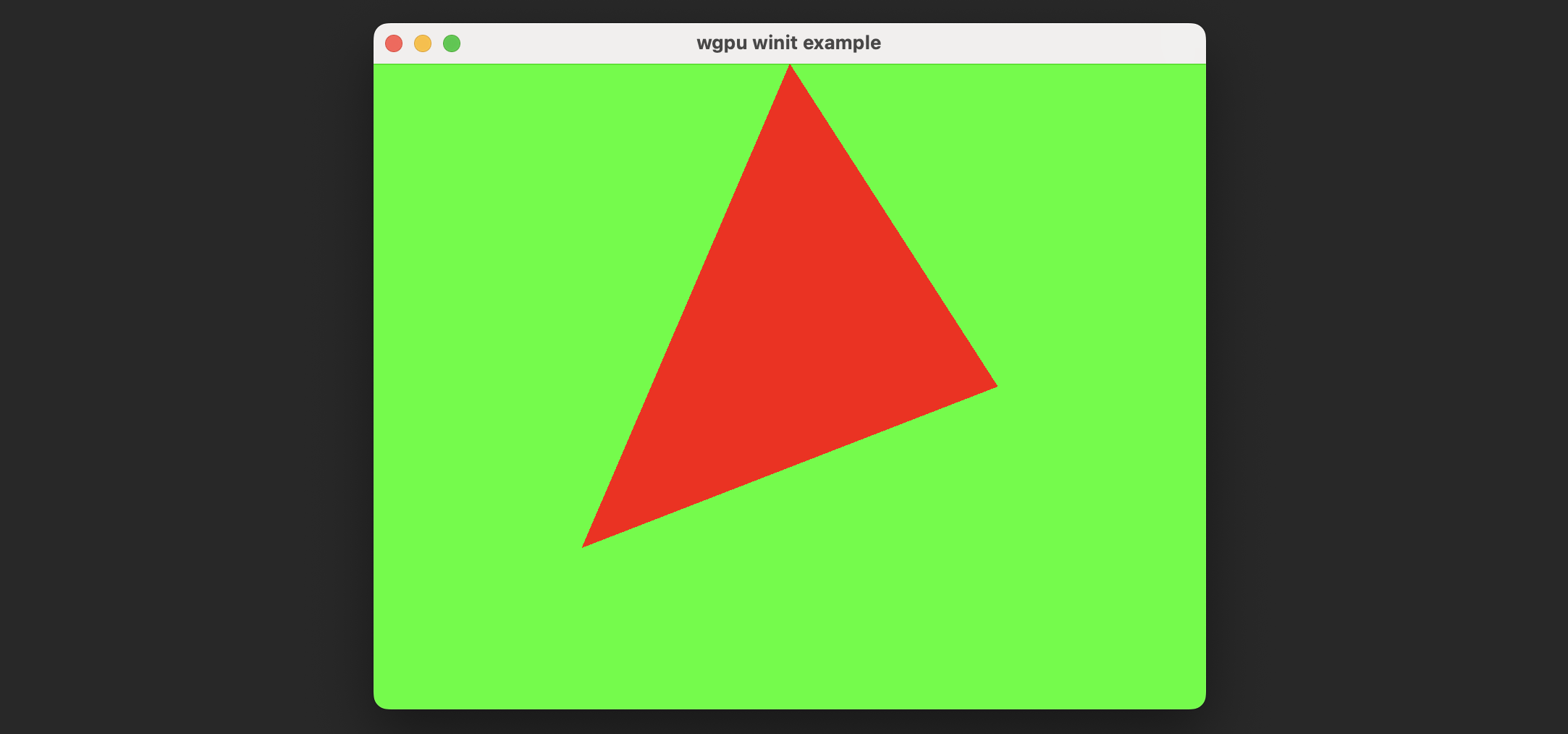
而对于片元着色器,我们暂时没有任何改动。因此,在一切准备工作结束以后,让我们运行程序,会发现最终渲染的三角形确实如我们所期望的结构那样展示了:
给顶点数据加入更多的信息
在本文中,由于我们的顶点数据结构体Vertex中只包含了一个类型为[f32; 3]的位置数据字段,因此在设置VertexBufferLayout的attributes字段的时候,我们只传入了一个VertexAttribute配置,并且其offset为0,代表了我们的一份在内存中的顶点数据,只包含一份属性数据,且是从偏移字节为0开始的。当然,正如前面提到的,顶点数据并非只会有位置数据,通常伴随着的还会有颜色信息、法线信息等。在这里,我们尝试给顶点加入颜色数据,好在着色器处理阶段能够定制三角形的颜色。
首先,让我们尝试修改Vertex结构体,加入一个颜色字段:
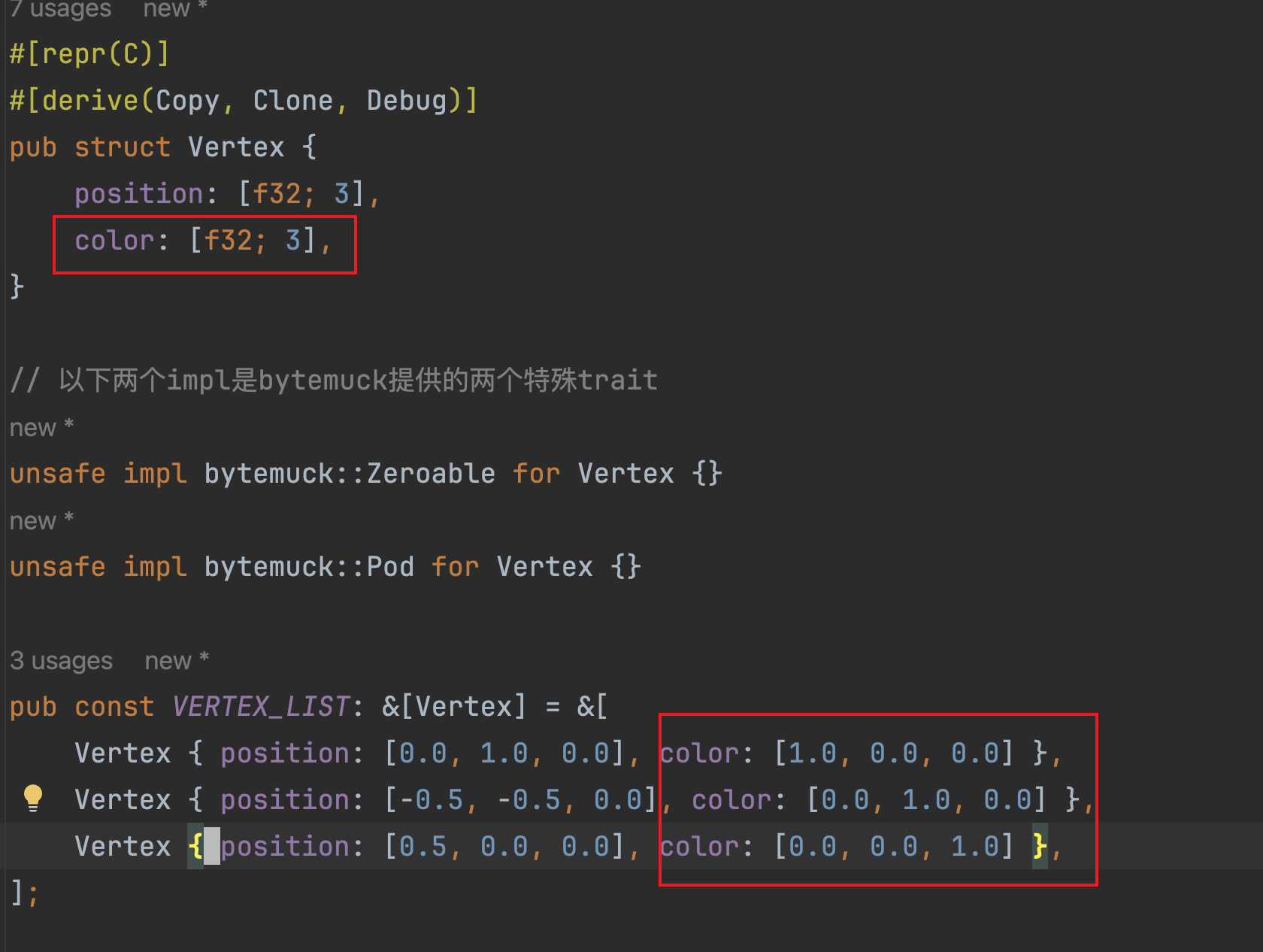
完成以后,可以想象到,把VERTEX_LIST数据转为字节数据放到顶点缓冲区以后,其内存布局会是如下形式:
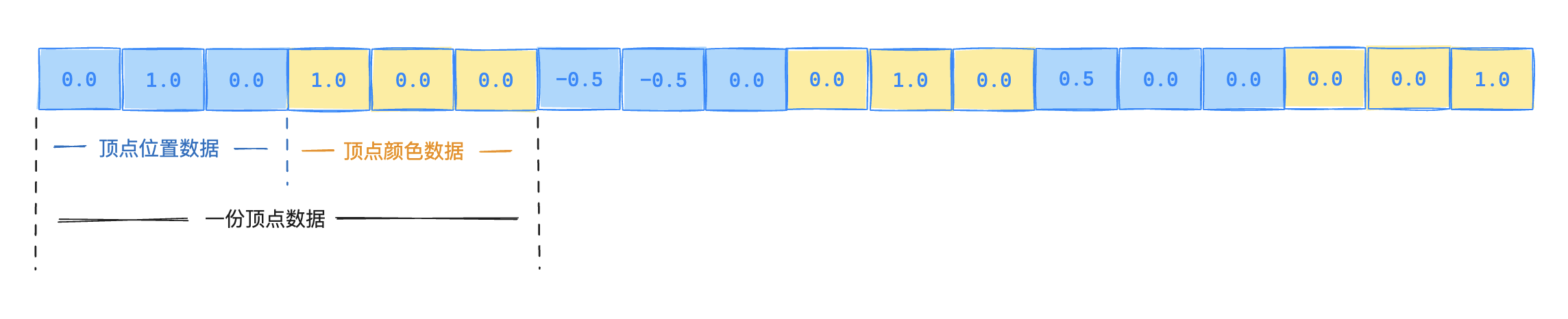
如果读者理解了前面提到的offset的含义,那么就不难想到,为了让顶点着色器能够访问到颜色信息。我们需要将顶点缓冲区布局中关于attributes字段增加一条配置:
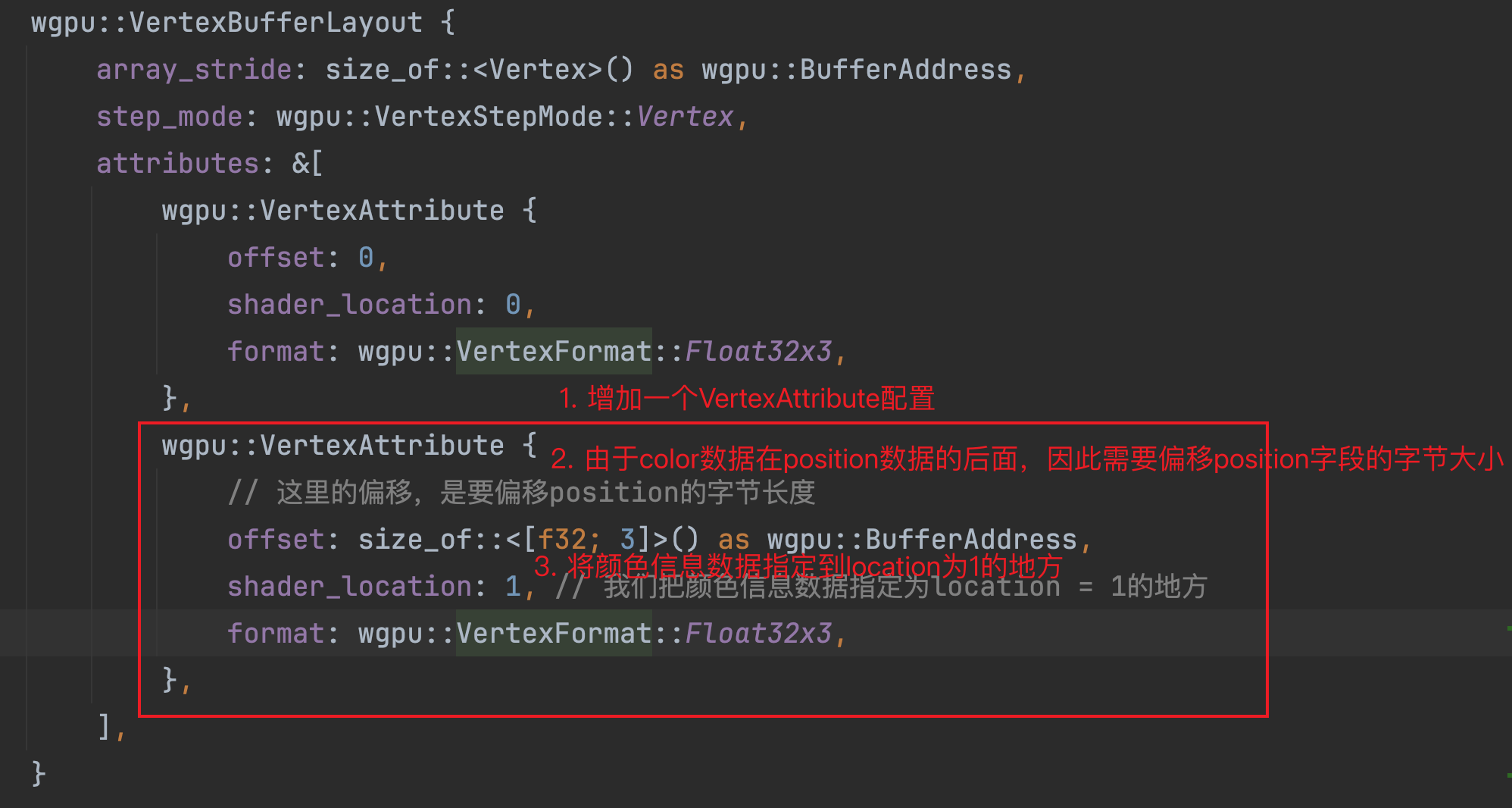
- 在顶点缓冲区布局对象的
attributes字段,在原有基础上,再插入一份VertexAttribute配置,代表了要配置颜色信息; - 对于新加的
VertexAttribute,其offset字段填入的值是偏移过position字节数据长度; - 将颜色信息数据指定为着色器中的location为1的地方。
接下来,我们只需要修改着色器代码VertexInput结构体,增加一个color字段,
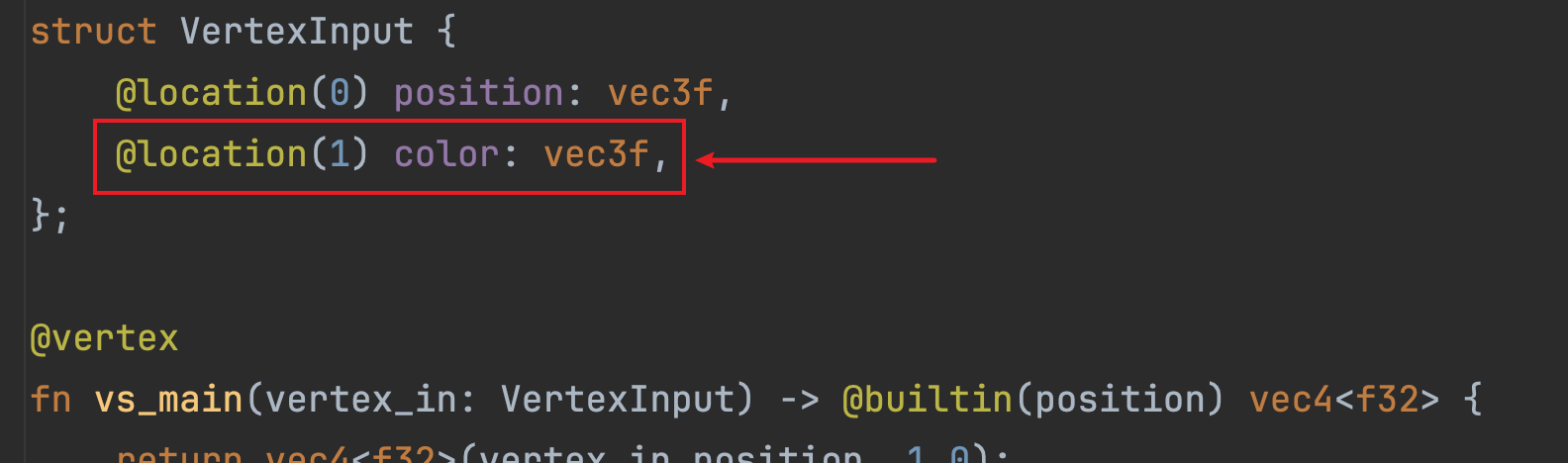
此时,渲染管线在构造这个VertexInput实例的时候,就能知道除了原有position字段数据外,还会把显存中的一份顶点数据的后面float32x3的大小数据映射到@location(1) color: vec3f上了。
当然,仅仅给VertexInput增加color字段,对于我们最终的渲染效果目前来说是没有任何影响的,因为我们压根儿没有消费这个color字段。为了消费这个字段,并让最终渲染的三角形的颜色产生变化,接下来就让我们关注一下着色器代码,看看还需要做什么。
首先,我们之前讲到过,对于顶点着色器的方法,我们返回的是@builtin(position) vec4<f32>,这意味着每次顶点着色器运行以后,会得到一个顶点的位置数据。在本例中,在所有顶点都执行以后,我们会得到3个顶点位置,渲染管线会拿着这3个位置构建一个三角形,并进行栅格化,再调用片元着色器,然后我们会再片元着色器中为每一个像素指定颜色。那么这里有一个问题:我们只能够在顶点着色器中返回每个顶点的位置吗?答案当然是否定的。除了直接返回一个@builtin(position)修饰的数据类型,我们还可以返回一个结构体,只要这个结构体中有一个字段用@bultiin(position)修饰即可:
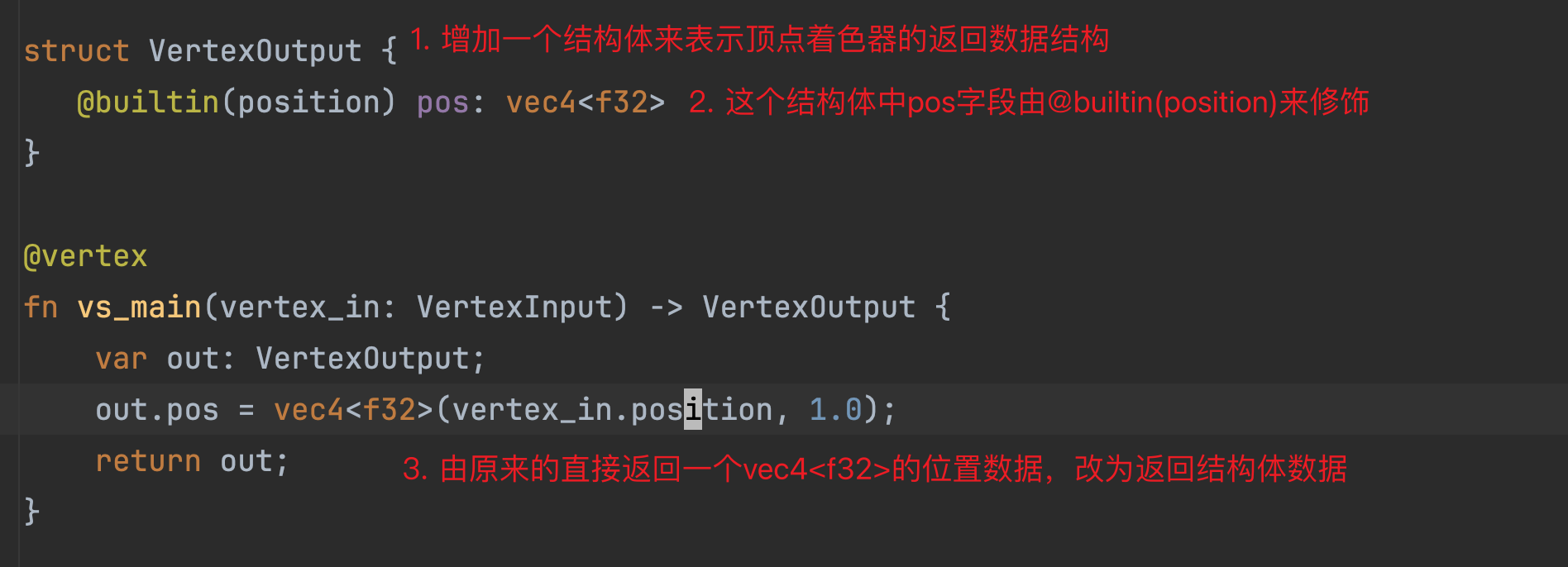
这段修改后的代码的效果其实和之前是一样的,只不过我们用过了结构体来包裹。在返回结构体的形式下,我们可以在结构体中加入一些其他的字段,并且,在片元着色器节点还可以访问到顶点着色器输入结构体数据:
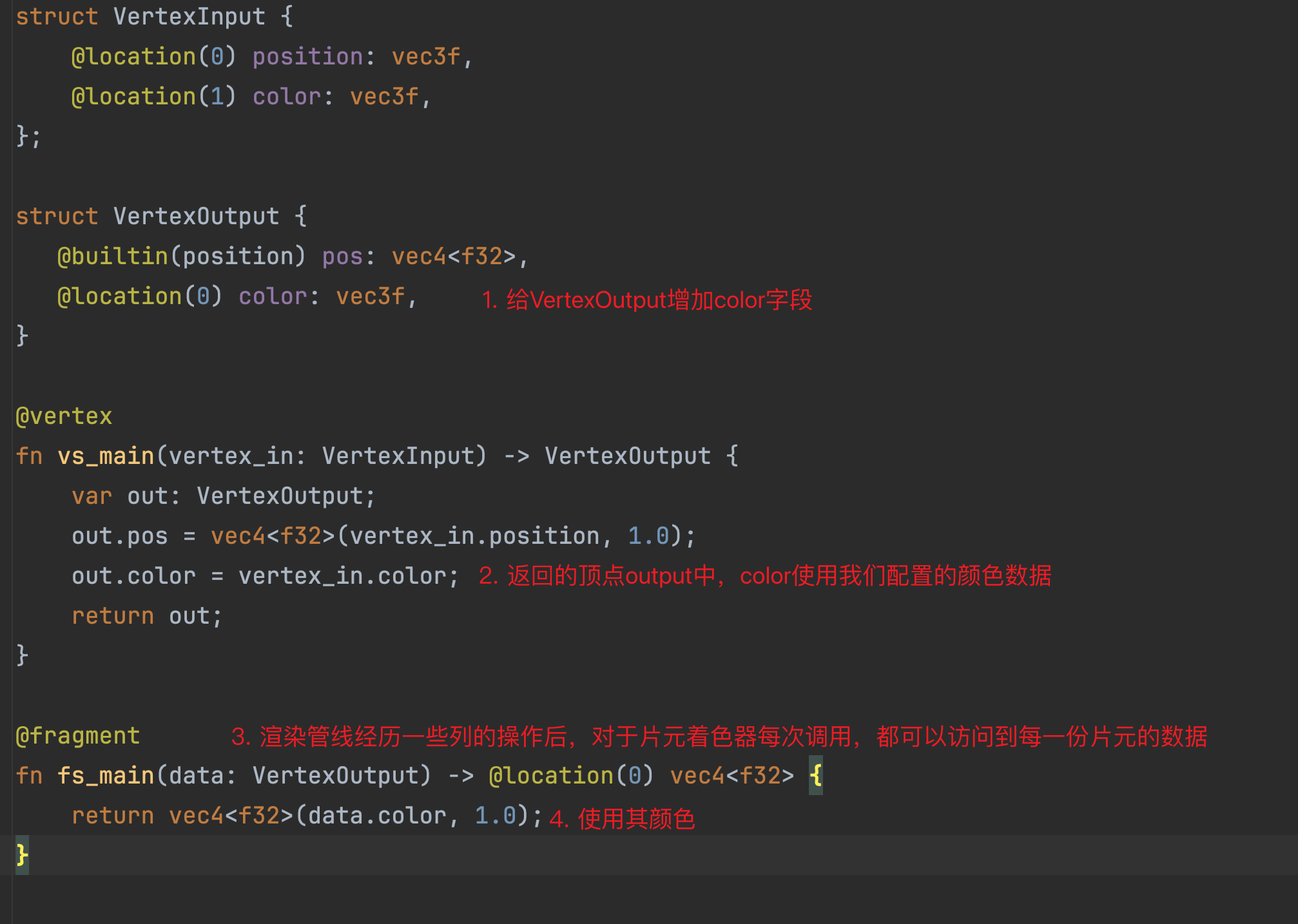
上述的着色器代码编写完成以后,理论上运行程序,你会发现如下的效果:
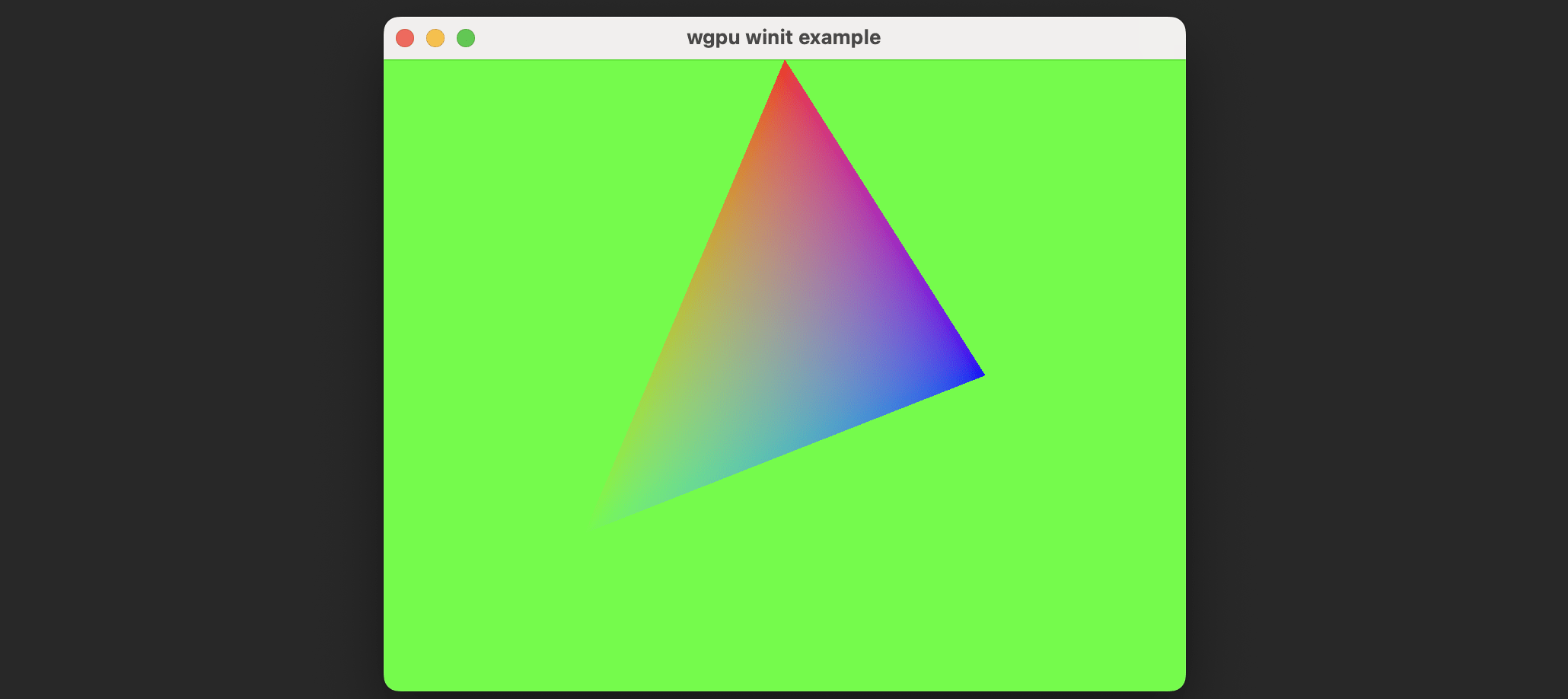
wow,一个渐变的三角形!然而,这就结束了吗?非也!
如何得到颜色
⚠️笔者水平有限,因此后面的内容笔者仅能靠自己目前浅显的理解进行总结,其中可能会存在一些不到位或不正确的理解,这里恳请相关专业人士对错误的内容批评指出。
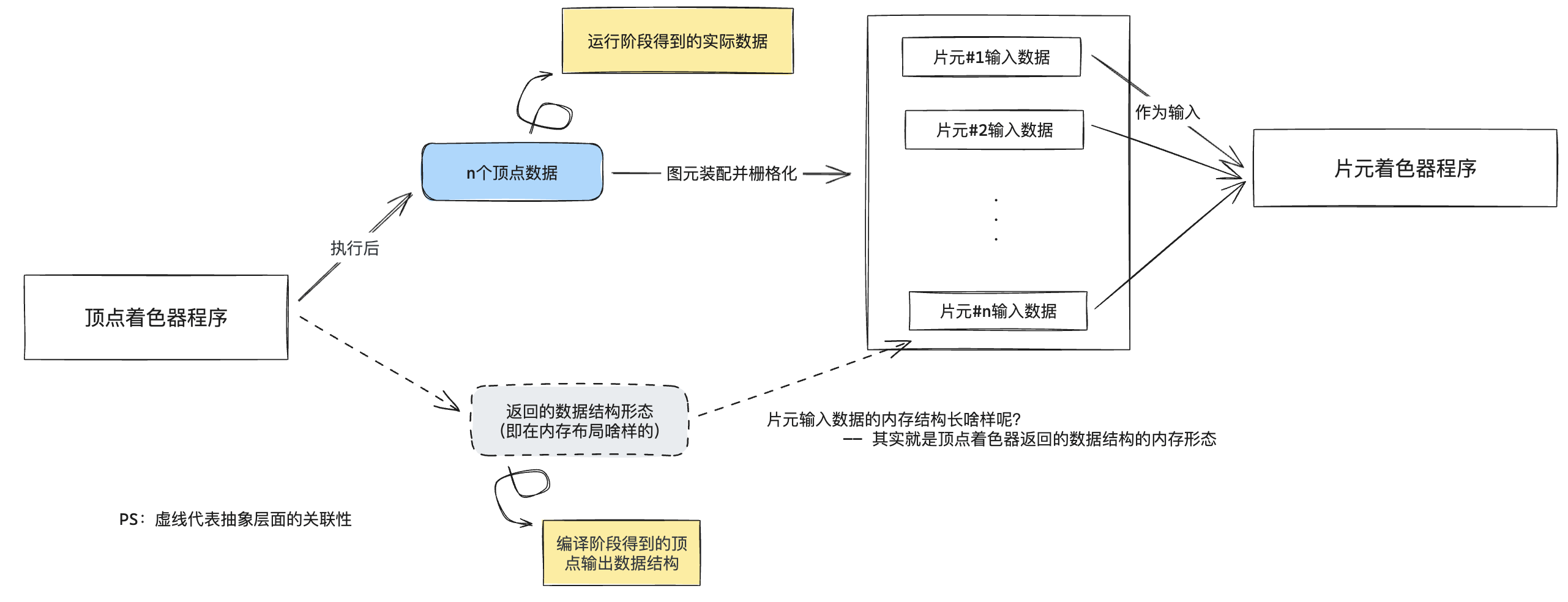
如果读者认真看到现在,并且仔细思考了以后,我相信你会有一些疑问。首先,目前我们只有3个顶点,那么顶点着色器理论上来讲只会被调用3次,也就是说,我们总共只会得到3个VertexOutput数据并返回给渲染管线,且这3个VertexOutput实例的color字段分别只会是(1.0, 0.0, 0.0)(红色)、(0.0, 1.0, 0.0)(绿色)以及 (0.0, 0.0, 1.0)(蓝色)。然而,我们最终渲染的三角形是一个渐变三角形。根据片元着色器的作用,它会在每一个像素处理阶段被调用,这是否能够表明一件事:片元着色器代码中的消费的color字段,和前面的VertexOutput的color其实不是一个东西?答案确实如此。

细心的读者会发现,在fs_main入参,尽管类型是VertexOutput,但我刻意的避免了使用vertex_output作为名称,而是使用了data,其实就在暗示从顶点着色器vs_main返回的VertexOutput跟这里片元着色器fs_main得到的输入VertexOutput实例并不是一个东西。让我们开拓下思维,结构体的本质是什么?实际上,结构体只是一种对内存数据的具名表达而已,在这里我们仅仅通过了VertexOutput这个具名的描述内存数据形态的标识作为了顶点着色器和片元着色器的桥梁而已。
换句话说,如果我们改成下面的代码,我们的程序同样能够正确的运行:
那顶点着色器输出的位置和颜色信息,最终是如何影响到片元着色器的输入的呢?对于渲染管线来说,在顶点着色器执行以后,它会得到三个顶点数据,而其中就有通过@builtin(position)标识的,能够表达位置信息的数据。很显然,有了三个点的位置信息,在图元装配结合光栅化以后,我们能够得到一个最终图形的上的任意一个像素点位置信息:

每一个顶点中我们都增加了一份数据用来表示颜色(color字段)。那么,对于三角面中任意一个像素的点位置的color字段数据,实际上是三个顶点颜色数据在此位置上的算法叠加:
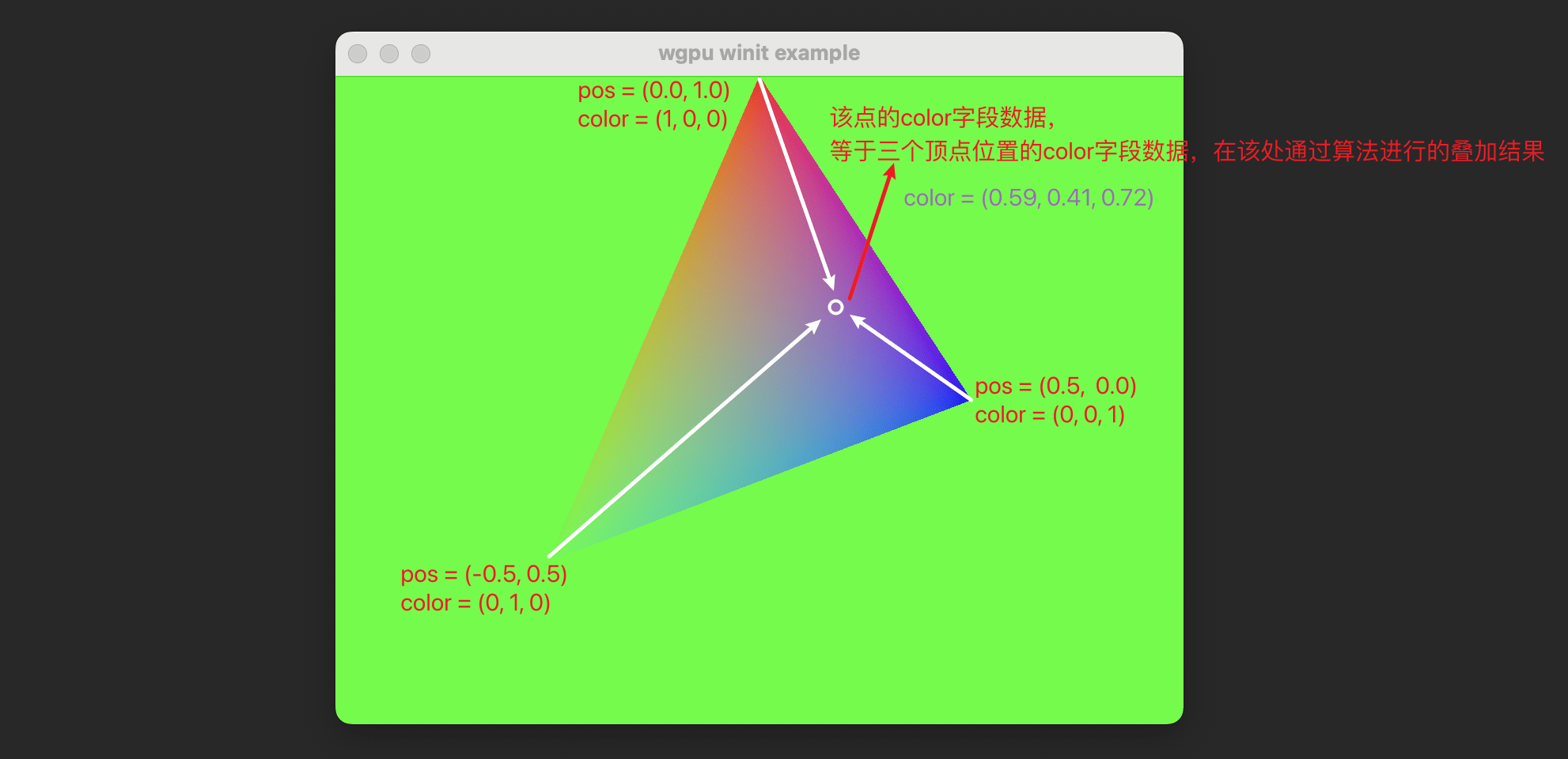
即,我们可以用一个方法来表达三角面上任意一个点的颜色:
1 | |
通过输入三个顶点的位置和颜色,以及任何一个三角面上的点位置,就能算出该点的颜色数据。但值得注意的是,在我们的场景中,我们对@location(0)位置的数据取名为了color,表明用该字段作为颜色字段,但是在内存中,管线只知道这里有一份类型为vec3f的数据罢了。所以,对应的更加通用的公式应该是:
1 | |
那么关于这个的具体实现在本文中不再细讲,但最简单的方式应该就是线性叠加,读者可以自行深入这块的内容。
关于@location
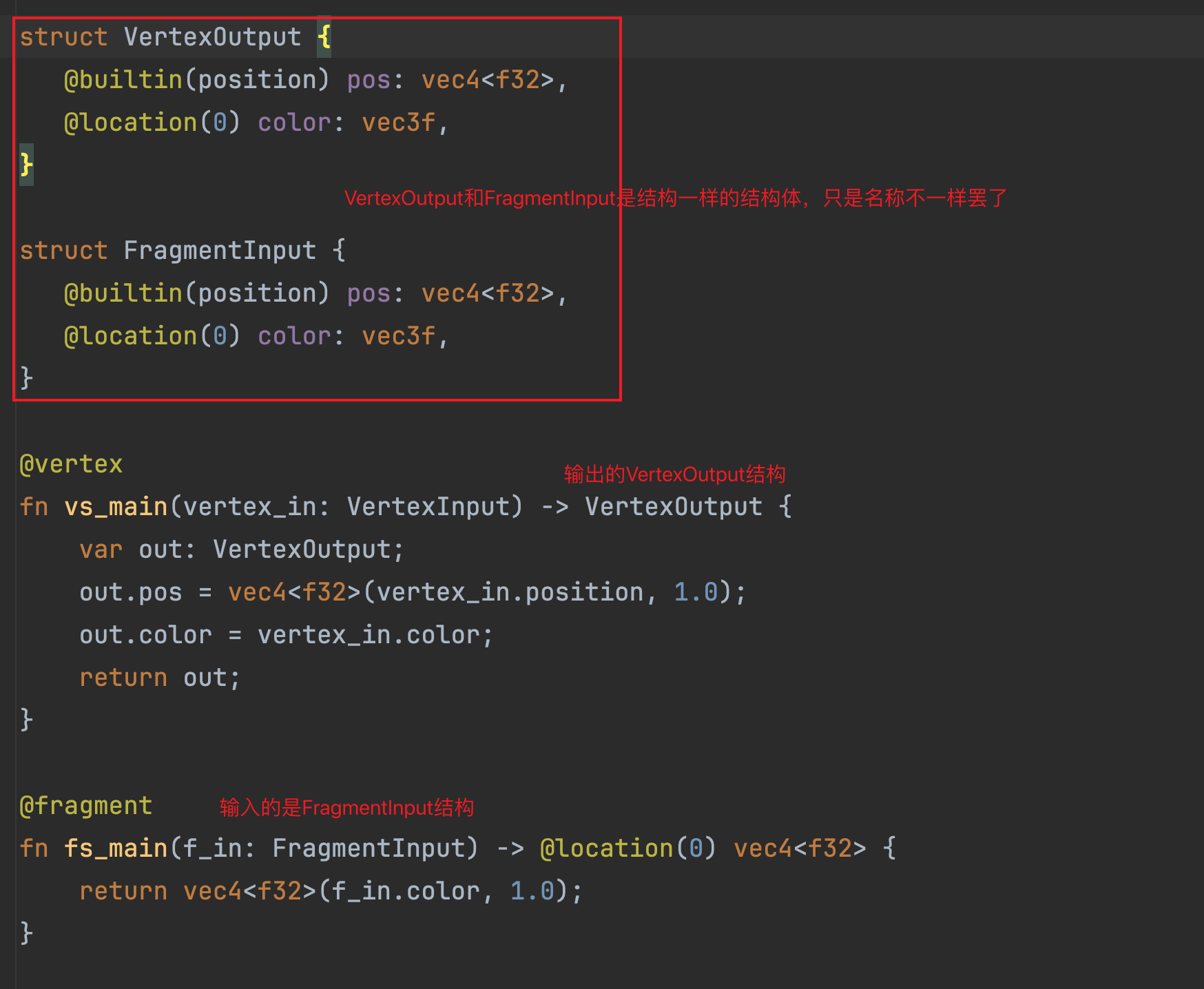
另外我们还需要着色器代码解释另一个东西。仔细观察代码,无论是VertexOutput还是FragmentInput结构体,我们都在color这个字段使用了注解@location(0)。在前面的VertexInput结构体的中的color字段我们使用了同样的注解,其含义是我们把一份内存中对应位置的数据设置为了着色器中一个结构体中location = 0的位置的字段。那么这里是不是也是同样的意义呢?答案确实是如此的。
读者可以这样理解,在光栅化后,每一次片元着色器的输入也是一份内存数据,这份内存数据我们同样可以使用一个结构体来访问(因为结构体是内存中的数据的可读性表达),但是结构体中的字段可以有很多个,每个字段究竟是内存中哪一块的数据,需要有一个明确的指明:
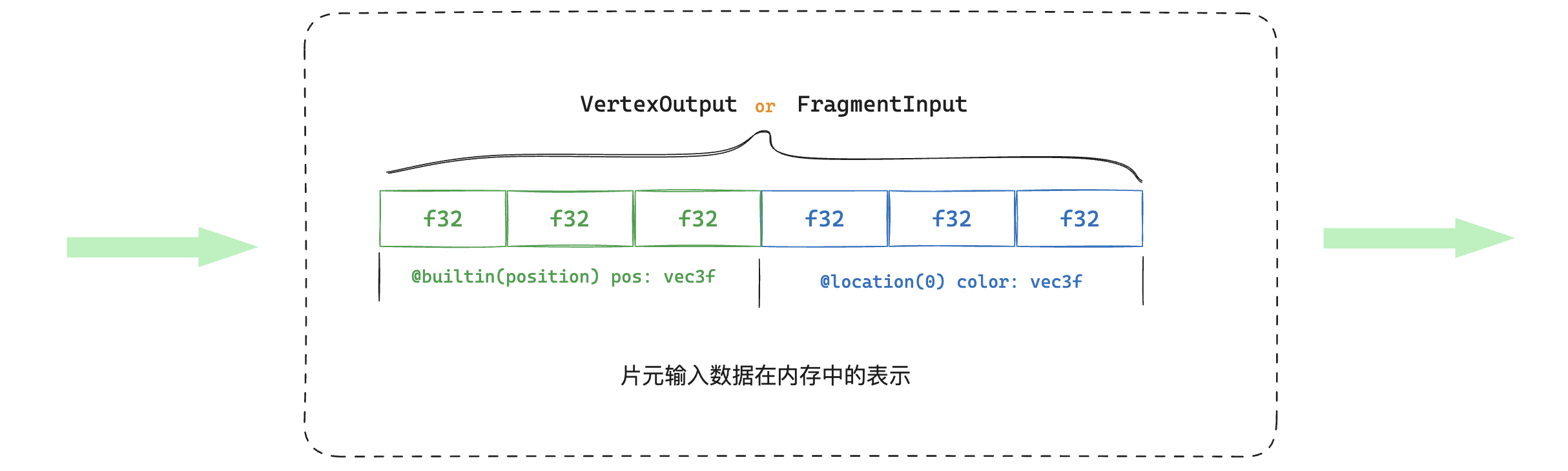
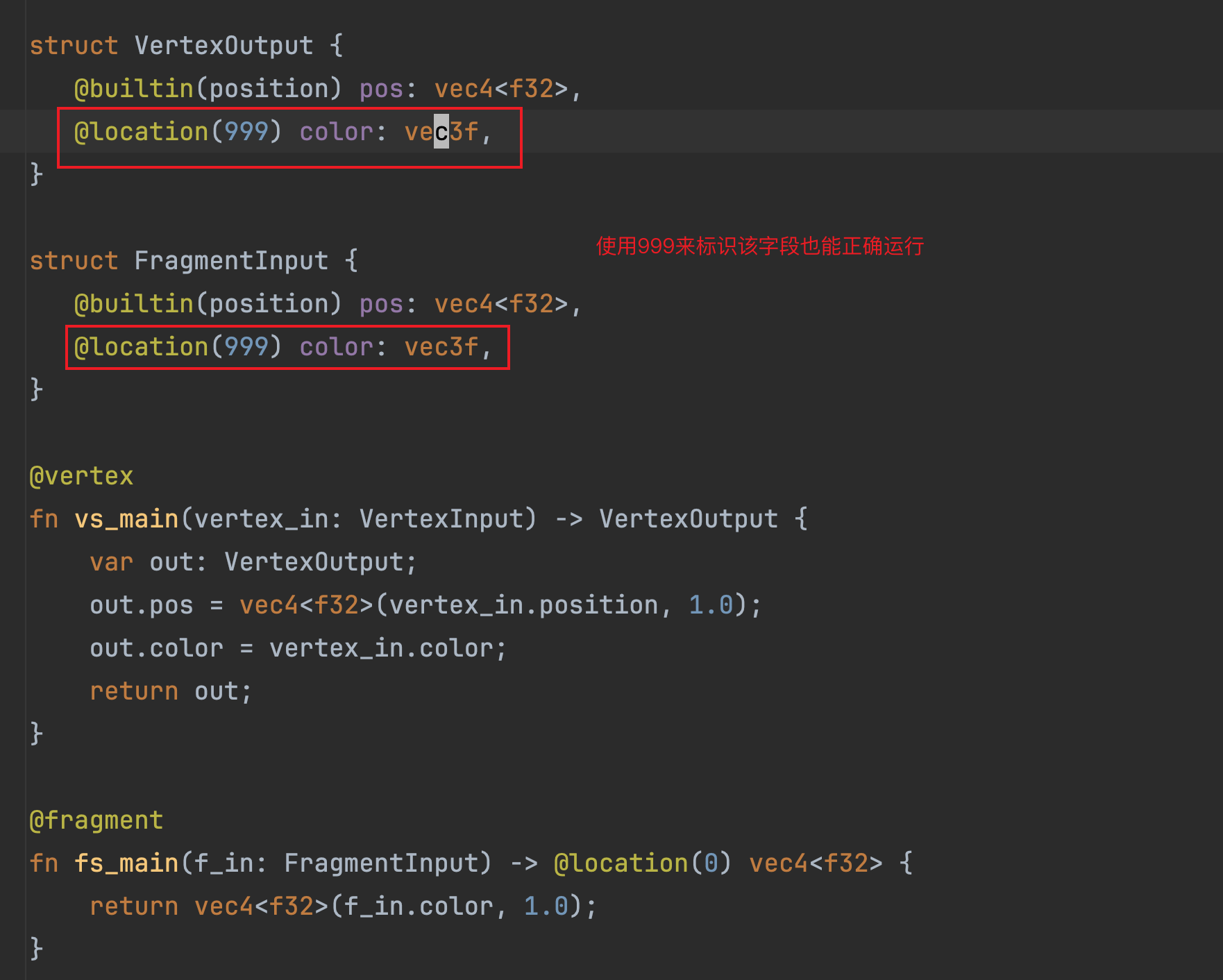
在上图中,无论是VertexOutput结构体还是FragmentInput结构体,其内存的布局是一致的,因此在片元着色器执行的时候,渲染管线提供的数据我们用上述两种结构体够可以表达对应的内存数据。再想的远一点,这个location只能是0吗?其实也不是,因为本质上讲,它是一段数据的标识,只是本例中,我们使用了0这个位置标识而已,如果你乐意,你还可以编写如下标识:
甚至,你还可以不编写任何的结构体作为输入,而是直接使用@location来定位:
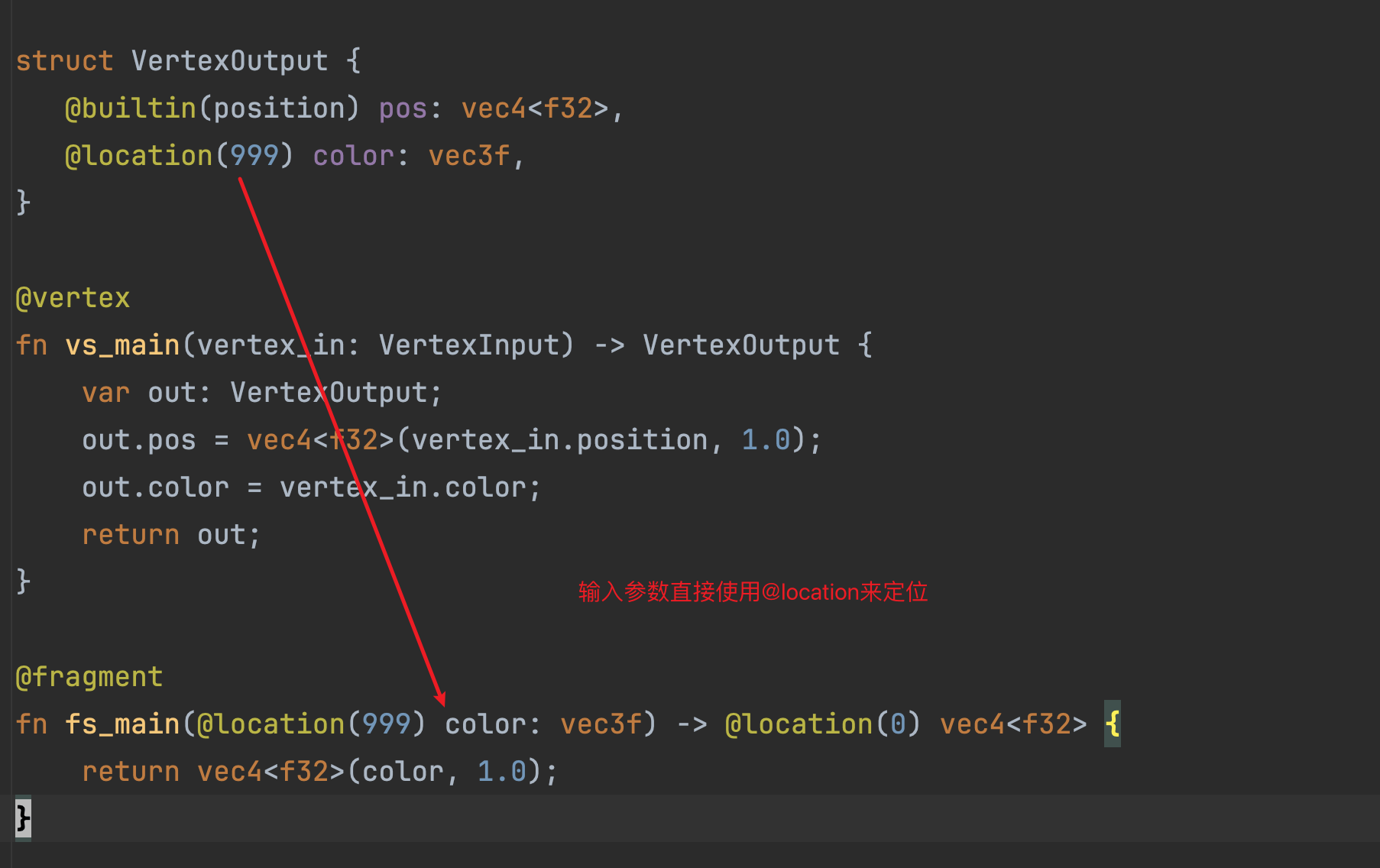
对于最后的一种使用方式,请读者自己揣摩一下~
写在最后
本文的内容较多引申了不少额外的内容,读者可以慢慢阅读消化,希望能够对认识wgpu以及图形学工程有更进一步的理解和认识。在接下来的内容,我们将会认识wgpu中有关于以及图形学工程相关的更多的内容,敬请期待!
本章的代码仓库在这里:
https://github.com/w4ngzhen/wgpu_winit_example/tree/main/ch03_buffer
后续文章的相关代码也会在该仓库中添加,所以感兴趣的读者可以点个star,谢谢你们的支持!